The Three Idempotencies of an Agent

{kind=link}
Two things go wrong in production agent systems, and engineers reach for the same word to describe both.
{kind=link}
Two things go wrong in production agent systems, and engineers reach for the same word to describe both.
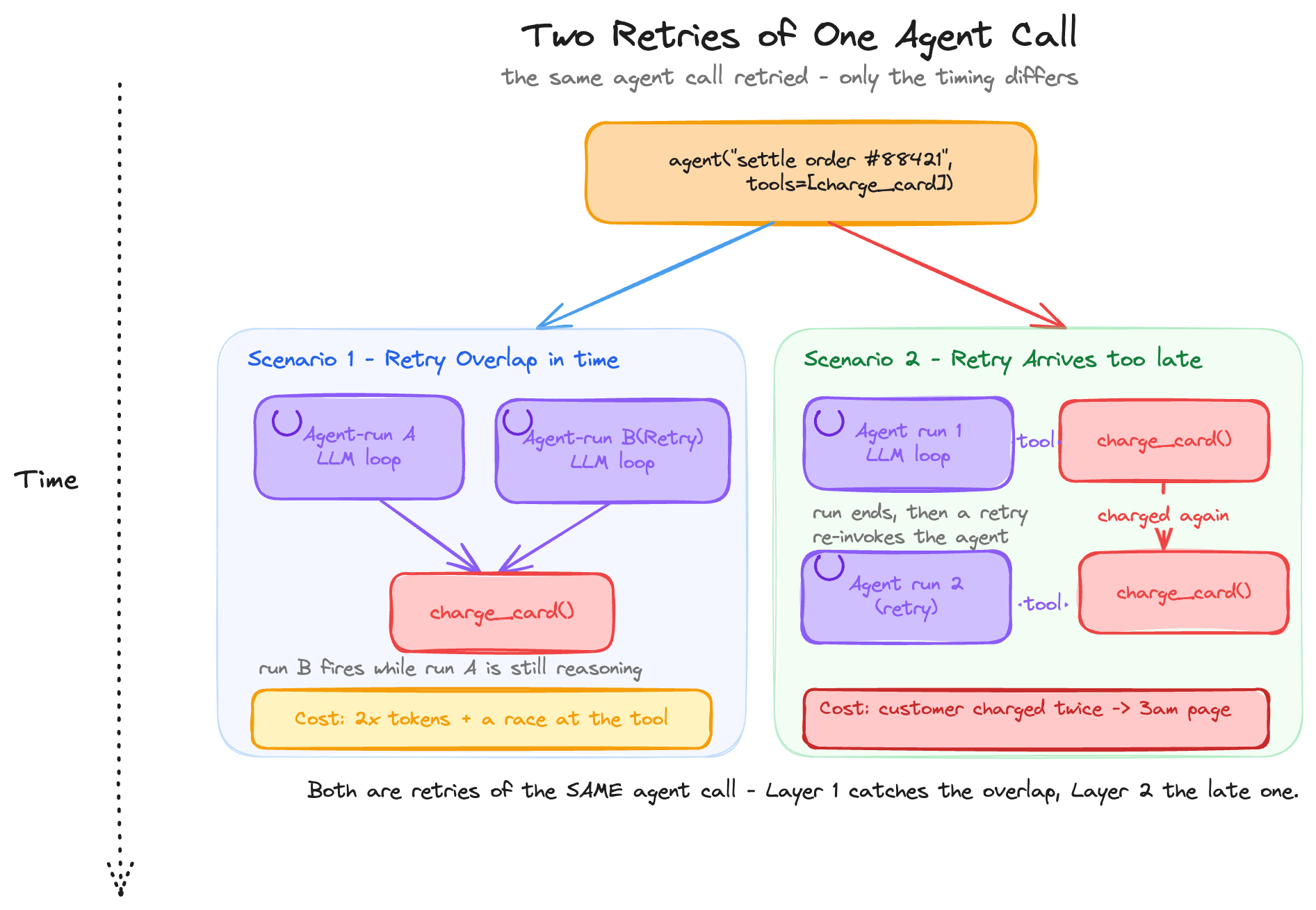
Here’s the first. A billing webhook fires your agent, something like `agent("settle the charges for order #88421", tools=[...])`. The run is slow. The webhook redelivers the same event, because delivery is at-least-once and this is routine, and a second run picks up the same order while the first is still going. Now two identical agent runs are grinding through the same expensive reasoning in parallel, burning twice the tokens. If both reach the charge step, you have a race you never designed for.
Here’s the second. The agent charges the card. The network blips before the confirmation comes back. The job retries to be safe. Now the customer has been charged twice for the same order. This is the one that wakes someone up at 3am.
Both get filed under _**“we need idempotency,”**_ the property that running an operation twice leaves the system in the same state as running it once. But they are not the same bug. They don’t share a cause, they don’t share a fix, and solving one does nothing for the other. I learned this the precise way: I spent a little over a thousand lines adding idempotency to an agent framework, shipped it, and then had to explain, to a colleague and (if I’m honest) to myself, which of these two problems it had solved. It was the first one. It does nothing for the second.
This matters now in a way it didn’t a year ago. Agents are moving from answering questions to taking actions that cost money and can’t be taken back: charging cards, placing orders, sending emails, moving inventory. The moment an agent touches a real side effect, every failure mode that distributed systems spent decades naming arrives at once, and the vocabulary hasn’t caught up. So one word gets stretched across three different failures. If you are putting an agent anywhere near something that costs money or can’t be undone, the rest of this is for you.
That gap between the two bugs turned out to be the most useful thing I could teach. “Idempotency for agents” isn’t one feature. It’s at least three different problems wearing one name, and most writing on the subject quietly picks one and leaves you exposed on the other two. This post is the map: what the three layers are, where each failure actually lives, and which layer I built versus which one is still an open problem.
Before the layers, here’s the one fact they all descend from.
In a normal distributed system, when you retry a request, you retry the same request. The bytes are identical. `POST /charge {amount: 4000, card: "x"}` fails, so you send the exact same payload again. This is why idempotency keys work at all. You attach a key to a fixed request, the server remembers that it has seen this key, and it dedups. The request is a stable, hashable thing. You can put it in a table.
An agent breaks this at the root, because the agent generates the request.
When you retry an agent, you don’t replay a fixed payload. You re-run a non-deterministic reasoning process that produces the payload, and that process can produce a different payload the second time. The run that first decided “charge $80, full balance minus the loyalty credit” might, on the retry, may decide “charge $100, full balance.” It might call the same charge tool with subtly different arguments, or take three tool calls to get there instead of two. Same goal, different path, different requests.
So the foundational tool of backend idempotency, dedup on the request, has the ground pulled out from under it. There may be no stable request to dedup on. _**The thing you would use as a key is itself an output of the dice roll.**_
Hold onto that, because it’s the difference between the three layers. Layers 1 and 2 are mostly classic distributed-systems problems that happen to occur inside an agent. Layer 3 is the one that’s genuinely new, and it’s new for exactly this reason.
{kind=link}
This is the duplicate run from the opening: the same logical request fired twice while the first is still in flight. An orchestrator retries a slow run; a redelivered webhook spawns a second run for the same order. (A double-click counts too, but that’s the frontend’s job; the ones that bite are programmatic.) Both are live, so you pay for two full reasoning loops at once, and if both reach a side effect, you have a race you never designed for.
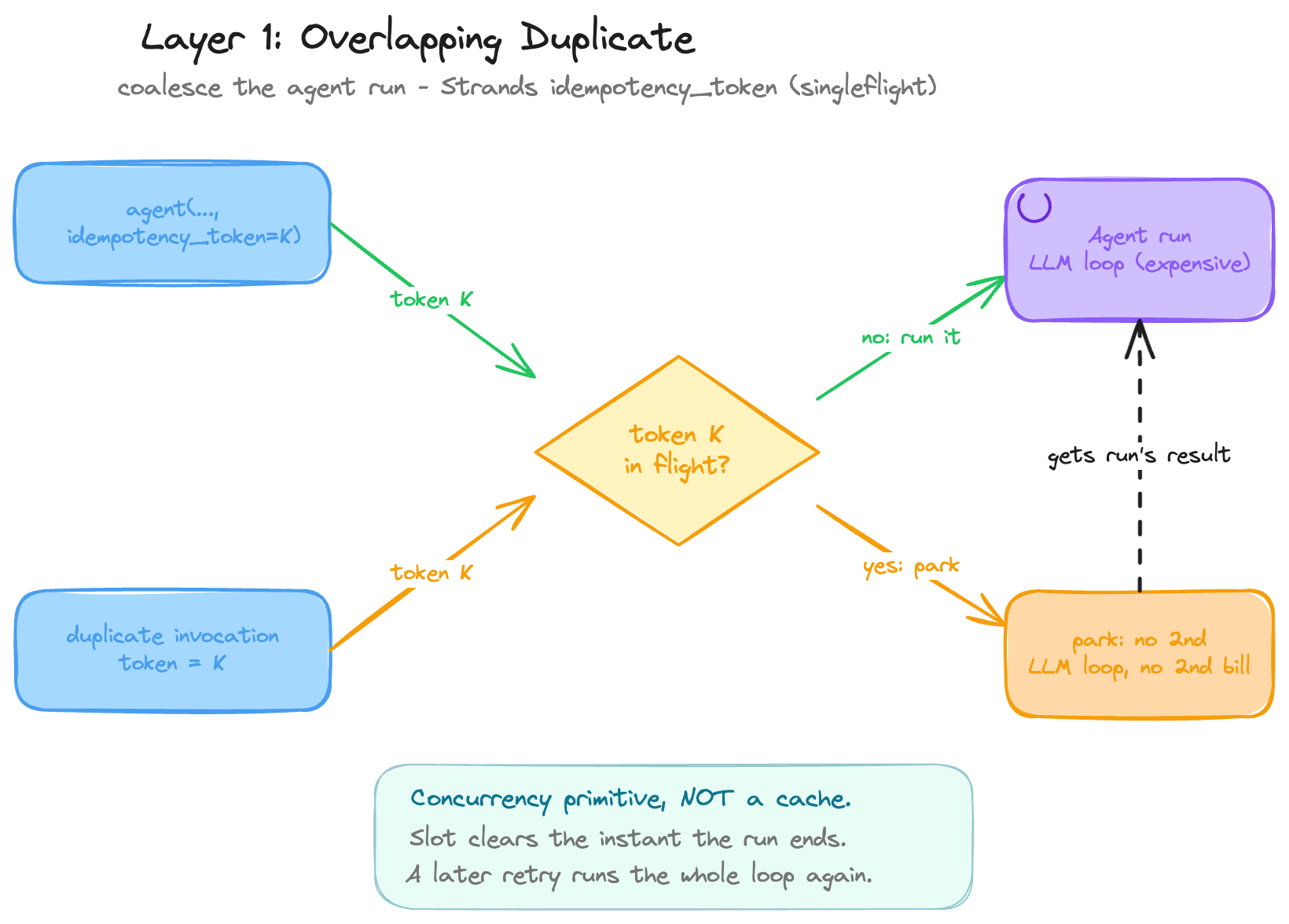
This is the layer I built: a feature called `idempotency_token` in Strands, an open-source agent SDK. I’ll walk through it as the decisions it actually was, because in hindsight it looks small (a token, some coalescing), and the thousand lines weren’t the feature. They were the cost of finding where the boundary goes.
**The shape.** An agent instance holds mutable state, so by default it won’t run two calls at once: a second concurrent call just throws. The token carves one exception into that. Give two overlapping calls the same token, and the second doesn’t run; it waits for the first and takes its result. One run, two happy callers, no double bill, no race, no failures. A different token, or none, and you get the old throw. That’s the whole feature: when a duplicate of something already running shows up, coalesce instead of crash.
Three decisions made that work, and none was obvious.
**Decision 1: opt in, not always-on.** The tempting version is a global “always idempotent” switch; I did the opposite. You ask for it on a single call. A blanket guarantee would promise more than this layer can keep (it can’t save you from the double-charge, that’s Layer 2), and only you can say what “the same request” means. The same order? The same prompt? Whatever you put in the token becomes your definition of “same,” and the agent honors it.
**Decision 2: coalesce, don’t cache.** This is the property that surprises people, and it’s the line between this layer and the next. While the original is still running, a duplicate waits and receives its result. The moment the original finishes, that result is gone. Nothing is stored. Send the same token a second later and the whole thing runs again, top to bottom. So this isn’t memory: it never remembers what happened, it only notices what is happening right now and attaches duplicates to it. (If you’ve used Go’s singleflight, it’s exactly that: a coalescer, not a cache.)
**Decision 3: the boring part was the hard part.** Most of those thousand lines went into making a duplicate wait and then wake up with exactly the right result, which sounds trivial and wasn’t. The obvious approach didn’t work; what did reads like a few lines of “wait here,” and the cost was finding out those were the only ones that worked. (An early version could deadlock outright.) The unglamorous half was the hard half.
**Why this matters more than it looks.** Classic backends solve idempotency in storage (a dedup key, a unique constraint), and concurrent duplicates barely matter, because each request is over in milliseconds. An agent call is the opposite: a loop that runs for seconds or minutes, where a duplicate isn’t a cheap no-op but a second expensive run. So “_what’s in-flight right now?_” becomes a real question, and answering it for one process is all the token does. Run two instances and you need shared state outside them all.
And here’s the honest limit, the whole reason this post exists: it does not make your charge idempotent. The token guards the invocation as a black box. The original still runs its full loop, including the real `charge_card`, and the duplicate never enters it. Because the slot clears the instant the original finishes, it does nothing for a retry that lands after, the one you most want protected. For that, we leave Layer 1 entirely.
{kind=link}
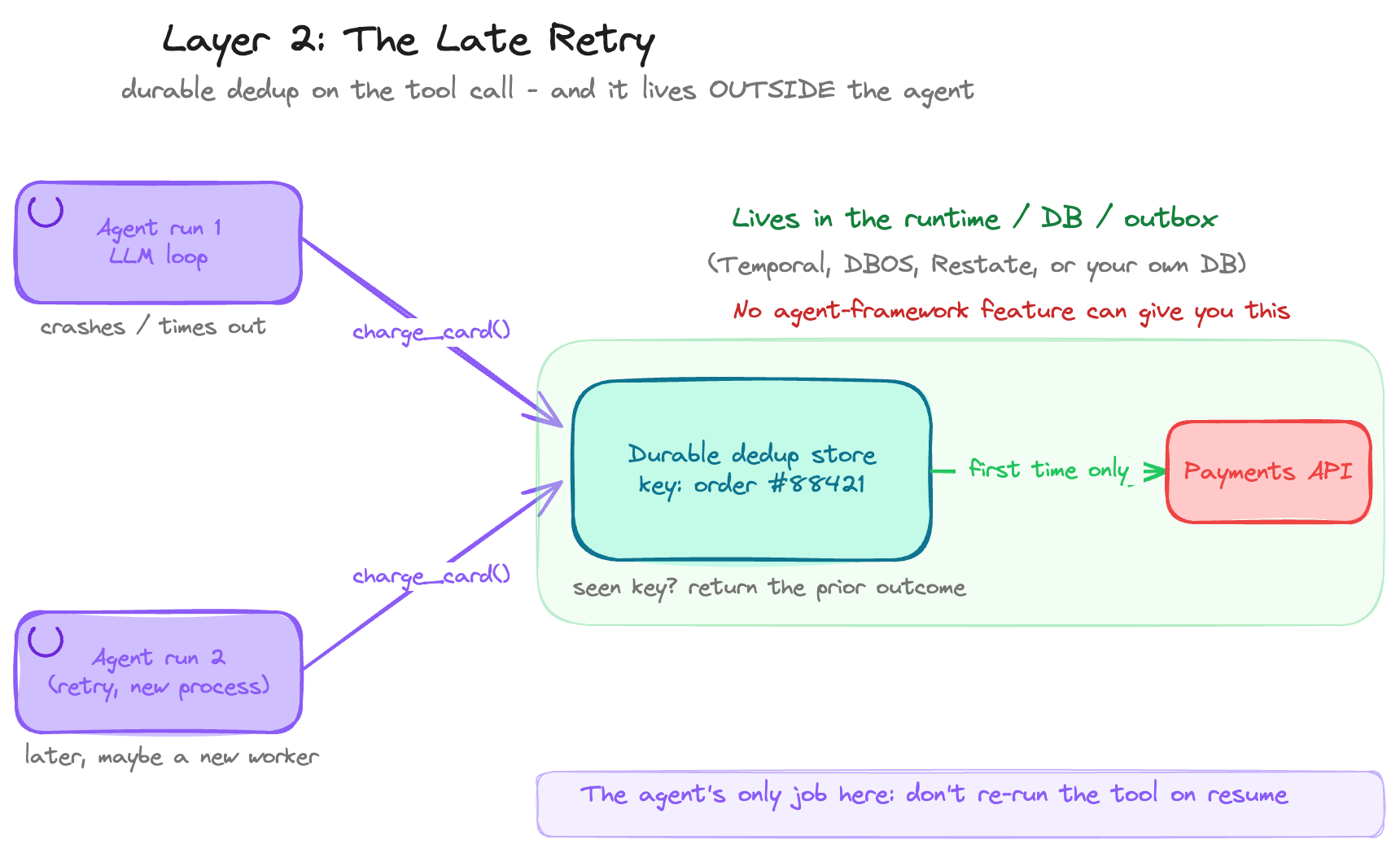
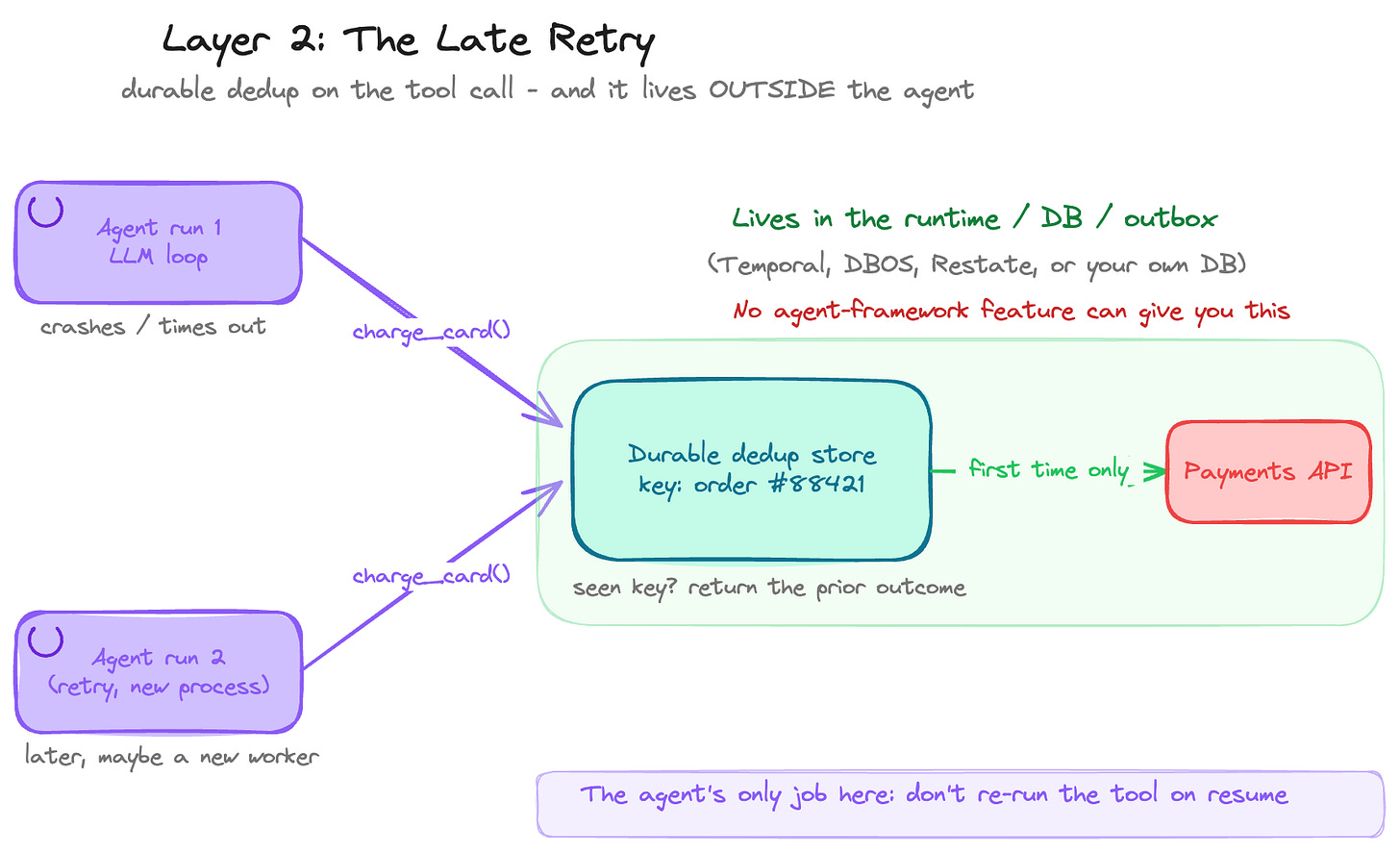
This is the double-charge. The agent charges the card and returns, or it crashes, or it times out, or the worker dies. Either way the caller isn’t sure it succeeded, so it retries: maybe on a different worker, maybe after the original already hit the payments API. There’s no overlap for Layer 1 to catch, because the first run is over. And Layer 1’s whole strength, being in-memory and in-process and in-flight, is exactly why it’s useless here. A sequential retry lands in a different moment, often a different process, with an empty slot. The coalescer has nothing to coalesce. This isn’t concurrency anymore. It’s memory that survives.
What it needs is the classic answer, with no LLM cleverness in it: a durable record of what happened, keyed by something stable, written somewhere that survives a crash, and checked before the irreversible action runs. “Have I already charged order #88421? Then return the prior result instead of charging again.” Stripe’s idempotency keys, the outbox pattern, a dedup table: things distributed systems have done well for years. Mercifully, a solved problem.
The only real question is where it lives, and the answer is: not in the agent. An agent instance is the wrong home for durable cross-process state. It comes and goes per request, it’s one of fifty replicas, and its memory dies with it. This belongs to whatever outlives a single run: a workflow runtime like Temporal, DBOS, or Restate, or your own database and outbox. The agent’s only duty is to not get in the way, to not silently re-run a committed charge on resume. So if double-charging is your real fear, the uncomfortable news is that no agent framework’s built-in “idempotency” will save you. The guarantee can’t live where the framework lives. You reach outside it.
And yet, even this isn’t the whole story. There is a way to do everything in this section correctly and still double-charge.
{kind=link}
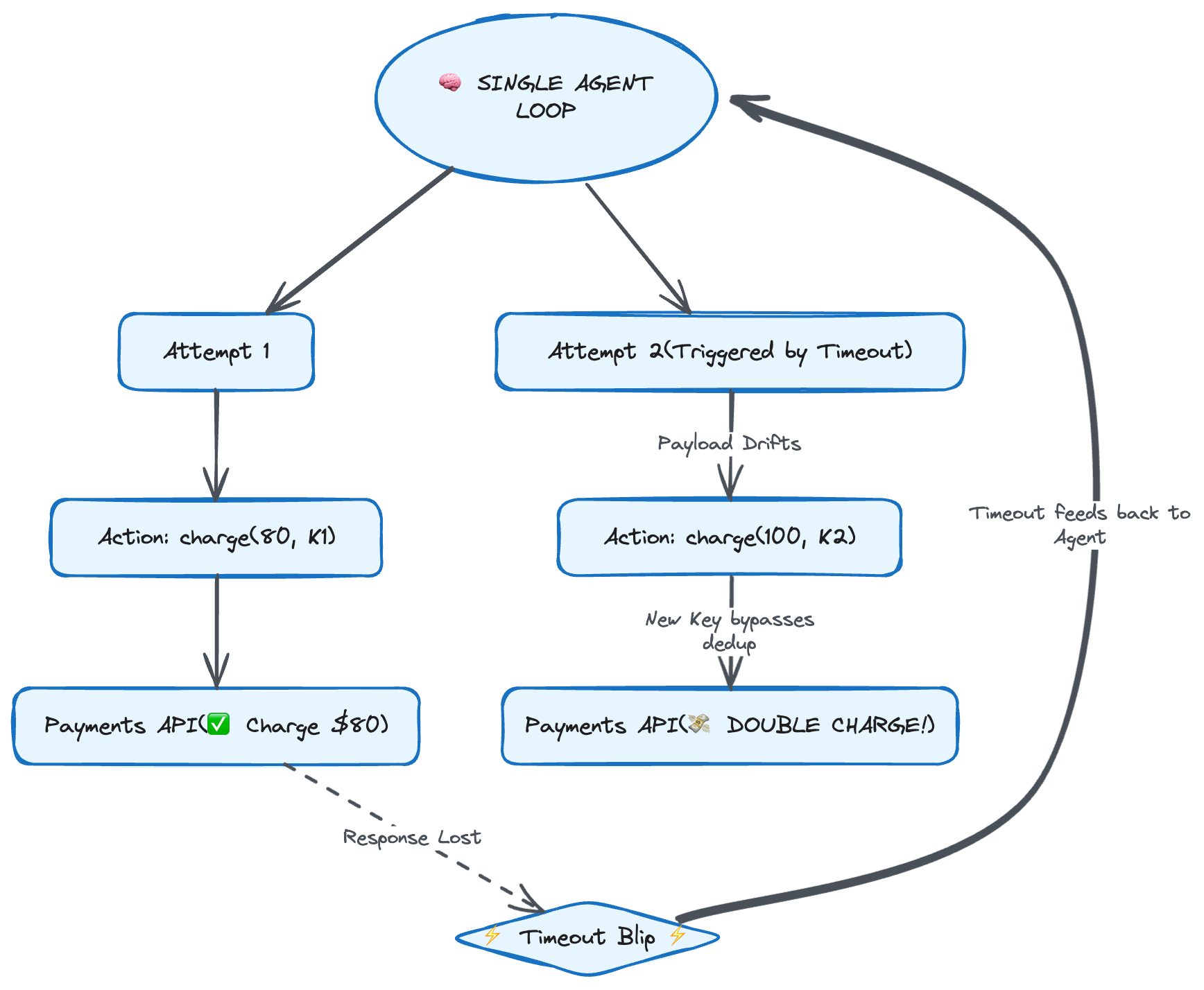
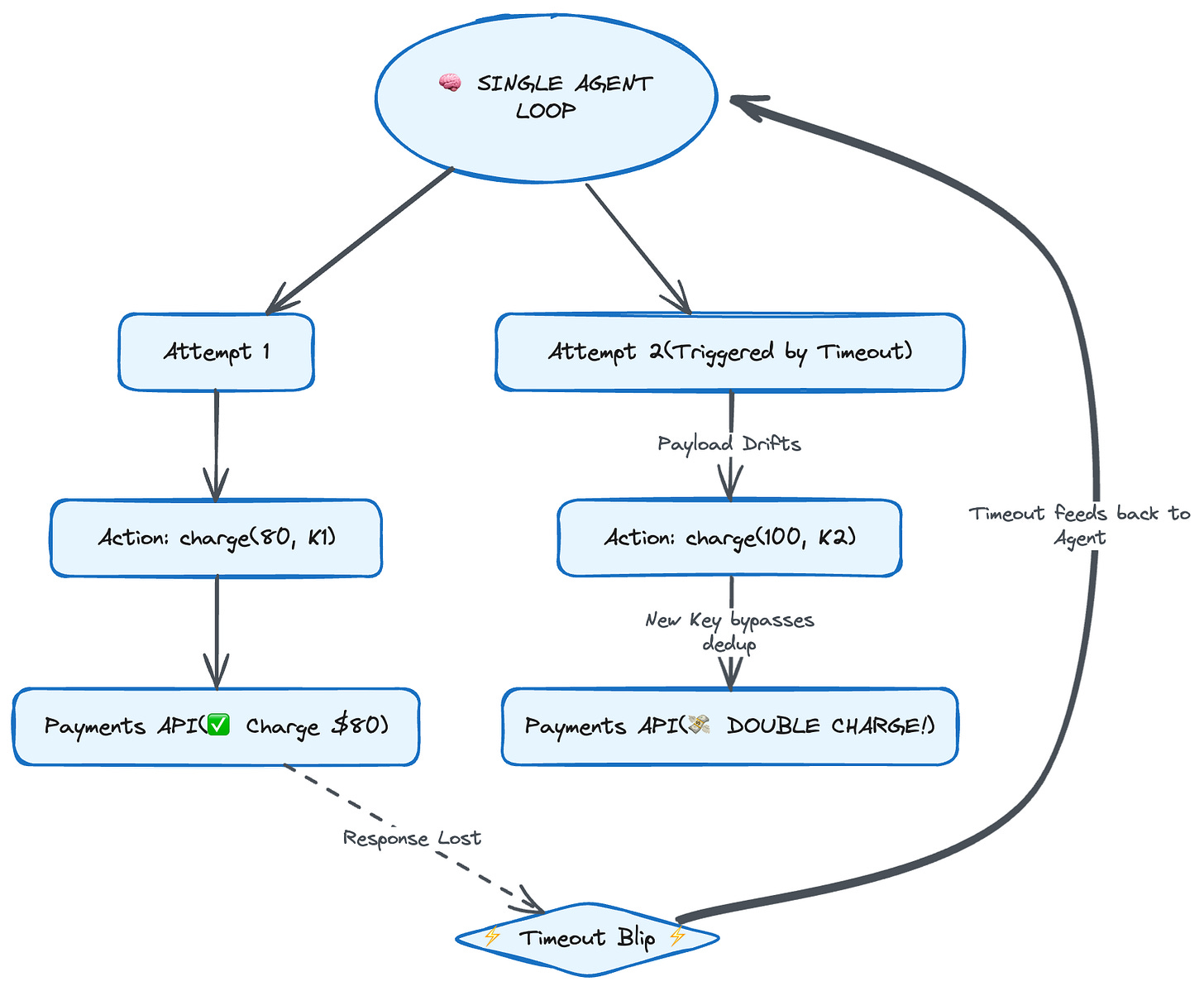
Put a durable idempotency key on your payments API. Do Layer 2 perfectly: the dedup table is live, keyed, and checked before every charge. Now watch it fail anyway.
The first run reasons its way to `charge_card(amount=80, idempotency_key=K1)`, full balance minus the loyalty credit, then crashes after the charge commits but before recording success. The retry starts fresh, and because the agent regenerates the request, its reasoning takes a slightly different path and produces `charge_card(amount=100, idempotency_key=K2)`. This run missed the credit. Different amount, different key. Your dedup table has never seen K2, so it waves the charge straight through. Two charges, every guardrail in place.
This is the layer with no clean analogue in classical distributed systems, the one I flagged at the top as the reason agents are different. Normally the retried request is byte-identical, so the key is stable for free. Here the payload is an output of the very process you’re retrying. **You can’t dedup on the request, because the request isn’t stable. You’d have to dedup on the intent, “the same logical charge as before,” and intent isn’t a field. It isn’t hashable. There’s nothing to put in the table.**
That’s the real frontier, and I’ll be honest: I didn’t solve it. Layer 1 is mine, Layer 2 is well-trodden, and Layer 3 is where the genuinely interesting unsolved work in agent reliability sits. Here are the partial answers people reach for, none of them settled.
**Thread a stable key through, from outside.** Don’t let the agent invent the key from its reasoning. Have the caller mint one stable key per logical operation and forward it, through the agent, into the tool, onto the API, so the key holds whatever path the reasoning takes. The catch: you now have to define what one “logical operation” is, and plumb its identity everywhere. The framework can expose a stable per-call id to forward. It can’t decide what counts as one operation.
**Derive the key from intent, not the call.** Hash the meaning (”charge this user for this order”) instead of the literal arguments, so two differently-phrased calls collide. The catch is obvious: which differences matter ($80 vs $100, same intent or not?) is a domain judgment, and getting it wrong silently merges or splits charges. You’re writing a similarity function for money.
**Two-phase the side effect.** Split “decide to charge” from “execute the charge.” Let the agent do the first, and gate the second behind a deterministic check it doesn’t control. Move the irreversible step out of the agent’s reach entirely.
Notice the through-line. Every real answer takes the identity of the side effect away from the agent’s reasoning and pins it somewhere deterministic: a caller’s key, a semantic hash, a confirmation gate. Which is the whole post in one line. The reasoning is the thing you can’t trust to hold still, so anything that must hold still has to be anchored outside it.
Step back, and the shape of the answer is reusable. Each layer sorted by two questions - _where does the duplicate come from_, and _where must the guarantee live to catch it._ Concurrency lives in-process, so the agent can own it. Durability outlives any single run, so it belongs to a runtime or a database. Intent-stability sits at the boundary between the agent’s reasoning and the world, anchored deterministically because the reasoning won’t hold still. Three layers, three homes — dictated by where the relevant state can physically survive, not by where you’d prefer to put the code.
That move isn’t special to idempotency; it’s how I’d reason about any reliability property you bolt onto an agent. The discipline is always the same: separate the _mechanical_ guarantee - which a framework can own, because it’s deterministic plumbing - from the _semantic_ one, which stays with you, because it requires knowing what the work means. Retries are mechanical until the model is confidently wrong (no backoff fixes a hallucinated tool name - that needs a circuit breaker around the reasoning); ordering and termination split the same way. Then put each guarantee where its state can live - because the agent’s reasoning is the one part you can’t make stable, and everything that must be stable gets anchored outside it.
Idempotency is just the cleanest place to watch that work - because the word fools you into thinking it’s one thing, and forcing it apart into three is the whole lesson.
Build it yourself, or wait for the ecosystem to absorb it? The three layers answer that too - and the industry has already made up its mind on two of them.
**Layer 1 is becoming a framework primitive.**`idempotency_token` is one early instance; native checkpointing in LangGraph, resumable steps in the newer SDKs, and the like are all frameworks pulling in-process safety into the box. Build it yourself only where yours hasn’t caught up.
**Layer 2 already has owners - and they aren’t the agent frameworks.** It belongs to the durable-execution runtimes: Temporal, DBOS, Restate, Inngest. The settled pattern is explicit now - the framework runs the agent logic, the runtime makes execution crash-safe and replayable. “Temporal _or_ my framework?” is treated as a layering question, not a competition. Don’t build durable dedup; put a runtime underneath.
**Layer 3 nobody is going to absorb** - and the durable-execution crowd says so themselves: their own docs are clear that checkpointing fixes crashes, not hallucinations or non-determinism. Even the standard key recipe (`workflow_id` + `step_id`) only holds if the workflow replays deterministically — the one assumption an agent breaks. Intent-stable identity isn’t a mechanism anyone can ship; it’s a contract about what counts as one operation, and only you can write it for your domain.
_So here is the honest truth about the ecosystem: frameworks are rapidly absorbing the mechanical layers, so just use off-the-shelf tools for those. But no framework will ever understand your business logic. The semantic layer is entirely on you to build_.
> Layer 3 is the wild west right now. How is your team handling intent-stability with agents? Are you threading keys, or doing two-phase commits? Let me know in the comments - Would love to see what the community is building.
_Want the code? The implementation for Layer 1 is in this PR, and the deadlock I mentioned got fixed in this follow-up. Both are part of Strands(AWS)._