Why Problem Statements Aren't Enough

Over the first three editions, we looked at why your career can feel stuck despite strong work: limited influence, the execution trap, and work that sounds smaller than it is when the context around it is missing.
Together, these patterns point to a deeper question:
So what actually helps your work become trusted, adopted, and valued at a broader level?
Some of those capabilities are obvious: technical depth, strong execution, and reliability. But others are easier to overlook.
One of the most important is **contextual range**: the ability to understand the technical, organizational, and business context around your work.
From the last edition, we know that context changes the perceived value of your work. This edition goes one layer deeper:
**Where does strategic context usually live?**
Most of the time, it is scattered across people, teams, systems, incentives, and priorities. You have to uncover it.
**The three types of strategic context**
Most organizations have three types of strategic context:
1. Technical context 2. Team or organizational context 3. Business context
**Technical context** is the context software engineers are usually most familiar with. This includes the codebase, system architecture, tools, infrastructure, technical constraints, and technical vision and strategy.
**Team and organizational context** is how work moves through people and teams. This includes team goals and dynamics, cross-functional dependencies, collaboration patterns, ownership boundaries, deliverables across departments, and alignment with company priorities.
**Business context** is about the business itself. This includes customer needs, product direction, revenue targets, market competition, profitability, board or shareholder expectations, and the risks or opportunities the company is trying to manage.
Each context answers a different question:
**Technical context tells you what can work in the system you actually have.**
**Team and organizational context tells you what can become real.**
**Business context tells you what is worth pursuing.**
Here’s one way to represent these contexts:
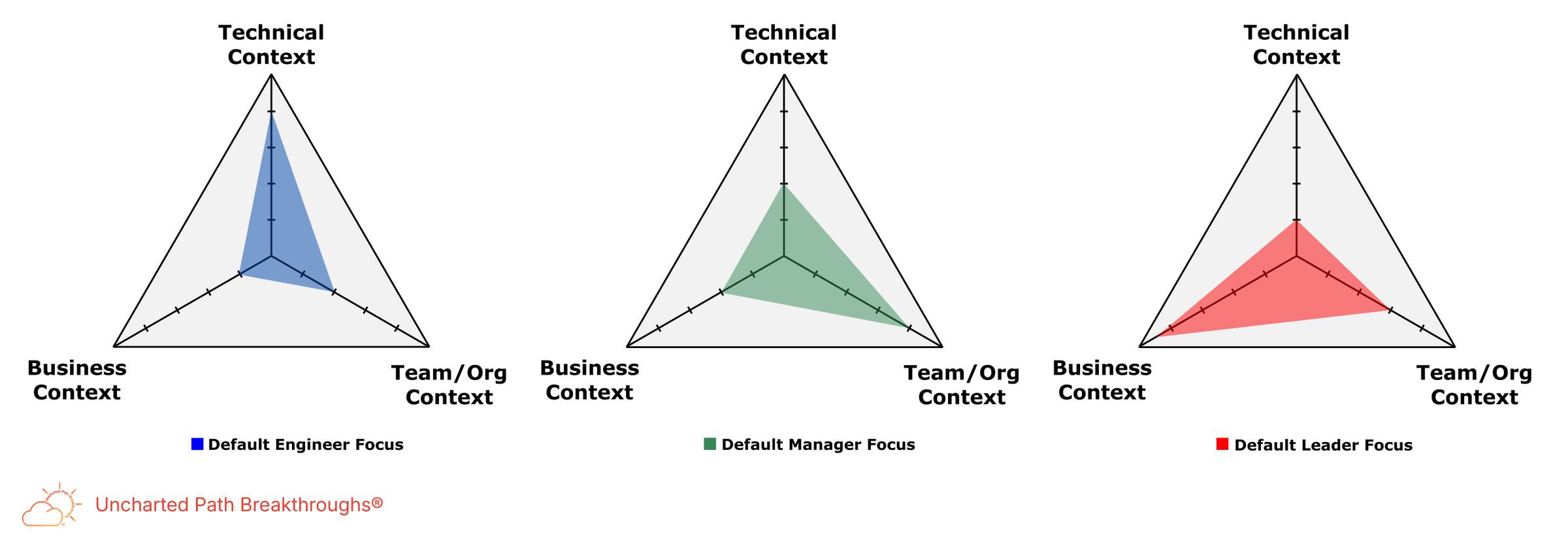
Engineers, managers, and leaders often pay attention to different parts of the same strategic context.
Needless to say, these are default starting points rather than rigid boundaries. Strong engineers, managers, and leaders can all operate across all three contexts.
But different job functions tend to enter the same problem through different default focuses.
Engineers may start with system design and code correctness, reliability, and maintainability. Managers may start with team capacity, ownership, coordination, and adoption. Leaders may start with business risk, investment, opportunity cost, and long-term leverage.
This is also why “it depends” is such a common answer in software engineering. At its best, “it depends” is a signal that the answer depends on context rather than a universal truth.
The more mature move is to ask: **What context are we missing?**
That question becomes even more important as your scope grows.
**The problem statement is where the work begins**
A few months after I joined a new organization as a Staff Engineer on the platform team, I was given a classic one-line problem statement:
**Build a Pub/Sub system for the company.**
On the surface, this can sound like a technical infrastructure project. Choose the right messaging pattern. Evaluate the right technology. Design the system. Build it. Get teams to use it.
But the one-line problem statement was only the beginning.
At the time, the organization had ~200 engineers and was primarily a Ruby shop, with some greenfield projects beginning to adopt Golang and limited use of Python in the Data org.
Different teams had already found bespoke ways to solve their asynchronous service-to-service communication needs.
Some had adapted Sidekiq as a _de facto_ Pub/Sub system. Others were using Twilio Segment, a customer data platform system, in ways that looked more like internal event distribution.
These choices made sense locally. Teams had problems to solve, and they used the tools available to them.
But across the company, the lack of a golden path was creating fragmentation, duplicated effort, and architectural debt. Anti-patterns were proliferating. New features took longer to ship, and production debugging became harder. Leadership was concerned that stretching purpose-built tools beyond their intended use would limit our ability to support future use cases cleanly.
So, the deeper question became:
**What kind of shared communication layer can this company adopt, operate, trust, and grow on top of?**
This question required all three kinds of context.
**Technical context: What can work here?**
The technical question could easily have turned into a technology debate.
Some engineers wanted Kafka for its low latency and high throughput. That preference was understandable. Kafka is powerful and widely used for event streaming.
But at the time, Kafka’s Ruby bindings were weak. The company also had limited in-house Kafka operational expertise, and leadership was hesitant to take on the burden of running a Kafka cluster ourselves.
We also evaluated Amazon Kinesis. It came with its own constraints, including weaker Ruby bindings and ongoing operational complexity around managing and scaling shards.
The technical context made the decision criteria clearer:
- What would work well in a Ruby-heavy environment?
- What could teams integrate with safely?
- What could the company operate with confidence?
- What would support a broad set of asynchronous communication use cases without creating unnecessary operational drag?
This clarity was important because a technically impressive solution that the company cannot operate, support, or integrate well becomes a future burden.
Technical context helps you understand what can work in the system you actually have.
**Team and organizational context: What can become real?**
The organizational problem was just as important.
Some teams were already considering building their own Pub/Sub systems. A few were willing to host something for the entire company. In some cases, their management was supportive. In others, alignment was less clear.
That created a second layer of questions:
- Who needed this first?
- Which teams would be willing to adopt it early?
- What use cases must the MVP support?
- What would make teams trust this system in production?
- What migration support would they need?
The company needed a shared golden path, but a golden path only matters when teams actually walk it.
A platform system becomes real when teams can adopt it, trust it in production, and stop solving the same problem on their own.
Team and organizational context helps you understand what has to change for the system to become real.
**Business context: What is worth pursuing?**
The business context gave the work its broader weight.
The cost was not just fragmented infrastructure. It was fragmented engineering capacity.
When every team solved asynchronous communication in its own way, engineering time went into rebuilding the same foundation instead of building product capabilities on top of it. Each custom path also made the company harder to operate, debug, and scale.
The value of a shared Pub/Sub system was that it turned a repeated engineering problem into common infrastructure, so teams could spend more of their time on differentiated product work.
Given the technical constraints, organizational adoption needs, and business priorities, we eventually chose SNS plus SQS.
Some engineers were disappointed because it was not a flashy solution. But it fit the company’s technical reality, had support from technical and business leadership, and gave teams a shared foundation they could actually adopt. We also reviewed the design and projected event volume with AWS technical experts, who confirmed that the approach was sound.
The simplicity of the solution paid off. Unlike Kafka or Kinesis, it required almost no ongoing operational maintenance from our team. The only significant operational issues we saw came from AWS outages, not from our own need to manage clusters, shards, or specialized infrastructure.
By the time I left the company 3.5 years later, the engineering organization had grown to 400+ engineers, and the system our team built had become the backbone for asynchronous inter-service communication across the company, supporting Ruby, Golang, and Python. It was handling 740 million messages per day.
A few key parts of the system also led to a patent, where I was the lead inventor.
The patent mattered to me because it showed that the technical depth was real. Expanding into organizational and business context made the technical work more valuable than it would have been in a vacuum.
Together, these three contexts determine whether your work stays local to one team or becomes a company-wide investment that creates broader technical leverage.
**The Staff+ operating range**
Looking back, the Pub/Sub project started with a clear company need: services needed a reliable way to communicate asynchronously.
But the problem statement only clarified the need. It did not define the full range of judgment required to solve it well.
The actual work sat at the intersection of three contexts at once. _That_ is the part many engineers miss when they think about Staff+ work.
And that is also the Staff+ Operating Range.
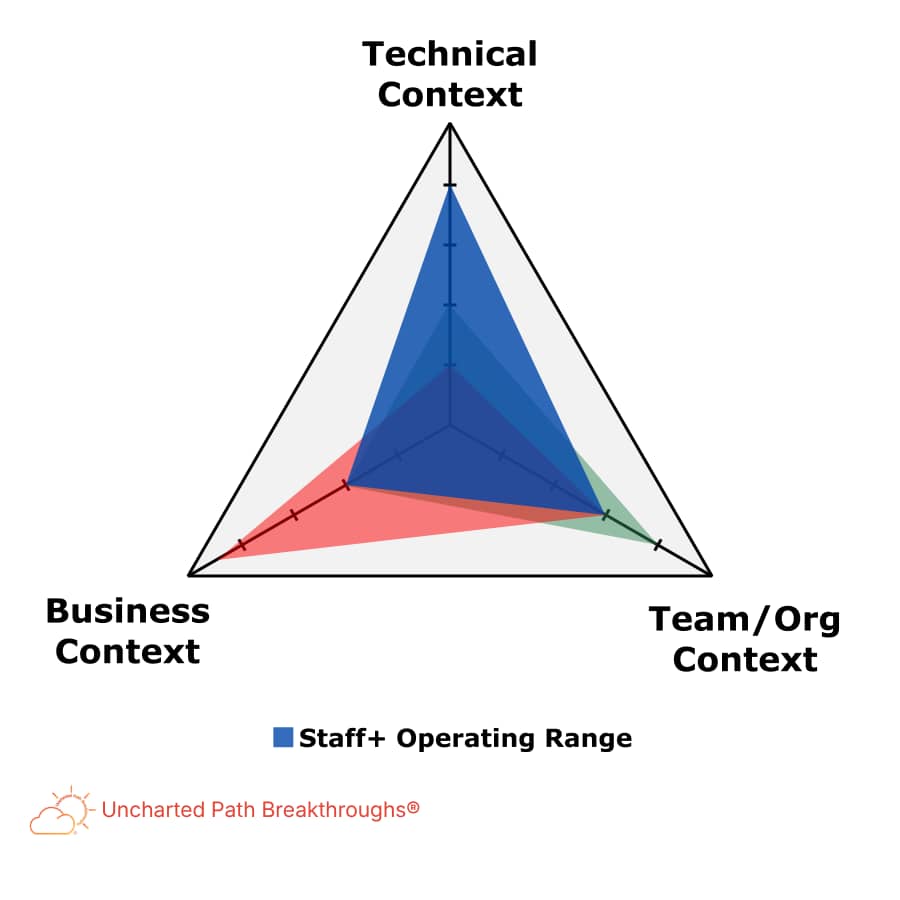
Staff+ engineers expand their operating range by applying technical judgment across technical, organizational, and business context, without needing to maximize every dimension.
To operate successfully at Staff+ levels, your goal is to expand your operating range so your technical judgment can account for organizational reality and business value, without needing to maximize every dimension.
When your work sits only in technical context, it may be strong, but it can stay too narrow.
But when it connects technical, organizational, and business contexts, it becomes easier for others to understand why it matters, support it, and build on it.
This is how strong technical work starts translating into real value for the organization.
Not every Staff-level project has to be company-wide. Smaller projects can still create significant value, and they are often where engineers begin developing the contextual range they can build on in larger-scope work later.