Auditable Workspaces for AI Coding Agents

{kind=link}
8 min read
8 hours ago
The pain in AI coding agents is already here
AI agents are becoming production labor. They write a growing share of the diff, and the bottleneck has quietly moved. After dozens of conversations with agent-heavy developers, the repeated complaint was never _“the model can’t write the code.”_ It was _“I can’t safely accept the code it writes.”_
If you run Claude Code or Codex daily, you’ve felt all six of these:
- Untracked prompts: You can’t improve them or reproduce a result. The prompt that shipped a change is gone.
- Lost context: Every session re-grounds from scratch. The agent forgets what it learned yesterday.
- Unsupervised tool use: Wrecked environments, malware, secret exfiltration — one `--dangerously-skip-permissions` away.
- Multi-agent token waste: Each agent re-reads the whole repo and every tool dumps its full output into the context window.
- Multi-agent conflict: Two agents on the same branch overwrite each other's work.
- Hard to audit: _Which prompt or model shipped this change? Which tools did agents use? Is there any environment modification?_ Unknown. Good luck at review time.
An agent run today is unsafe and opaque: untracked prompts, dangerous tool usage, conflicting multi-agents.
What h5i does about it
h5i(pronounced _high-five_) gives every AI coding agent a sandboxed Git worktree and records the evidence behind every change, including prompts, commands, network access, logs, policies, and reviews. An agent run becomes safe and auditable, and it all rides in your repo under git refs `refs/h5i/*`. No SaaS, no lock-in, works offline. Teammates who don't use it just see ordinary commits.
It solves all six pains directly:
- Prompt versioning — captured with each commit, so results replay.
- Persistent context — carried across sessions, no re-grounding.
- Supervised sandbox — a policy-enforced worktree per agent.
- Token reduction — raw output kept out of context, up to 95% less.
- Conflict-free orchestra — isolated worktrees, merged into one result.
- Easy to audit — risk-ranked review of every AI change.
The rest of this post is the end-to-end flow, the way you actually run it. Every command below is real, and so is every block of output.
1. Install
One install script, or build from source.
$ curl -fsSL https://raw.githubusercontent.com/h5i-dev/h5i/main/install.sh | sh
or build from source
cargo install --git https://github.com/h5i-dev/h5i h5i-core
Confirm it’s on your path:
$ h5i
h5i 0.2.6
2. Setup
Initialize h5i and wire the Claude Code / Codex hooks. This is a one-time setup. After it, the agents capture prompts, context steps, commits, and handoffs on their own. You don’t run those commands by hand.
$ h5i init✔ h5i sidecar initialized at /path/to/repo/.git/.h5i
✔ Claude instructions written to .claude/h5i.md (imported via CLAUDE.md)
✔ Codex instructions written to AGENTS.md
✔ Persona scaffold written to PERSONA.md (CLAUDE.md auto-loads it)
Note: h5i stores metadata in refs/h5i/notes and refs/h5i/memory.
These refs are NOT included in a plain git push.
Run h5i share push to share them with your team. Now register the hooks. `--wrap-bash` routes noisy Bash output through h5i's token-reduction filter; `--team` enables the peer-review coordination hook.
$ h5i hook setup --write --wrap-bash --team✔ Agent hooks configured:
Claude Code .claude/settings.json
Codex .codex/config.toml
SessionStart: h5i hook session-start · Claude PostToolUse: h5i hook claude sync (Edit|Write|Read)
Claude Stop: h5i hook claude finish · Codex Stop: h5i hook codex finish
Bash capture-wrap: h5i hook wrap-bash (PreToolUse · Bash) — Bash commands run through
h5i capture run: token-reduced summaries for large/failing output, full raw stored for recall.
Team peer-review: h5i team agent hook (Stop) — keeps an agent in an active round from
stopping while it owes work; surfaces review requests between turns.
→ open /hooks once (or restart) so configured agents reload hooks. Commit the wiring so your teammates get it too:
$ git add . && git commit -m "wire h5i hooks"
3. Track prompts and contexts
Once the hooks are registered, h5i versions your human prompts and every agent context step as Git objects, and trims noisy tool output along the way. Watch what happens when a command floods the terminal:
$ h5i capture run -- pytest -q pytest test failed · 1 failed, 1 passed (exit 1)
F test_calc.py::test_auth AssertionError AssertionError: expected 200, got 401
▢ h5i object ad110124e3b44f7d · tool-output · 597 bytes · 13 lines · ~68% fewer tokens (108→35)
rehydrate: h5i recall object ad110124e3b44f7d The agent sees only the one failure that matters, `not 240 green dots`. On a bigger run the savings are dramatic:
$ h5i capture run -- bash -c 'for i in $(seq 1 200); do echo "line $i ok"; done; echo "ERROR: boom" >&2; exit 1'bash generic error (exit 1)
line 1 ok (×200)
ERROR: boom
▢ h5i object 8497 dd0532aa3fda · tool-output · 2324 bytes · 203 lines · ~98% fewer tokens (1007→23)
rehydrate: h5i recall object 8497 dd0532aa3fda 98% fewer tokens, and nothing is lost, where the full raw output is stored out-of-band and recoverable any time with `h5i recall object <id>`.
Get Hideaki Takahashi’s stories in your inbox
Join Medium for free to get updates from this writer.
Remember me for faster sign in
Every commit an agent makes carries its prompt and model. Replay them straight from the repo:
$ h5i recall log --limit 2 commit 1 b7d294fa0630e0f99f11edbc21f69aef7bbf88a
Author: demo <a@b.c>
Agent: claude-code (claude-opus-4-8)
Prompt: "Add a sub(a,b) helper next to add()"
Message:
add sub() helper
────────────────────────────────────────────────────────────
commit d897b248a708e81612a60a478ea0625631f23b03
Author: demo <a@b.c>
Message:
init calc
Share it, or post a PR summary
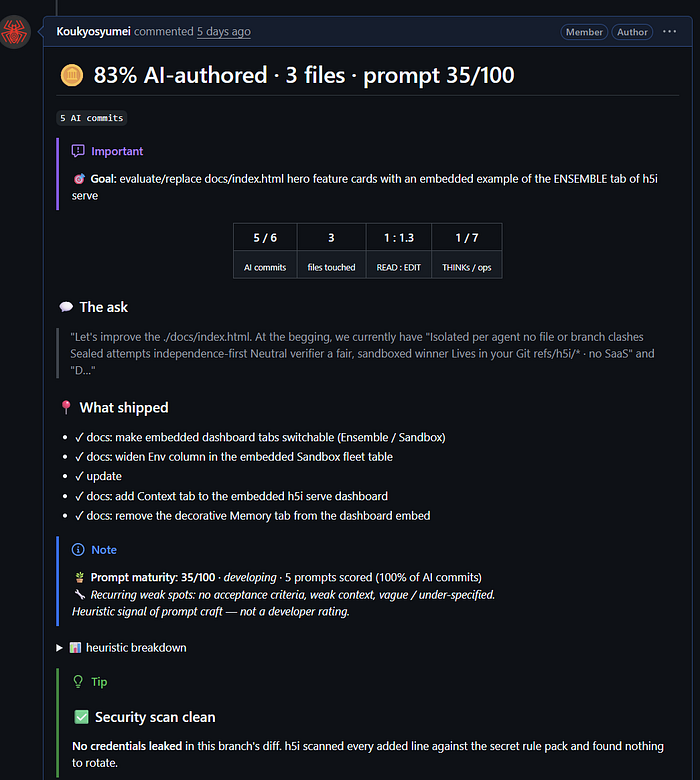
Push the h5i metadata to teammates, or drop an AI-usage summary (prompt quality, AI/human commit ratio, secret leaks, prompt-injection signals, and more) onto the pull request:
$ h5i share push
$ h5i share pr post
Press enter or click to view image in full size
{kind=link}
4. Give each agent a sandboxed environment
Here’s the crux of _safe acceptance_: let the agent run with permissions off inside a sealed box, then review its diff before anything touches your branch. `h5i env create` picks the strongest isolation the host can enforce, such as Landlock + seccomp on the kernel tiers, a network egress allowlist on the container tier.
$ h5i env create claude-env ✔ Created environment env/human/claude-env (isolation: supervised, profile: agent-claude)
base 1b7d294fa063 (from main)
branch refs/heads/h5i/env/human/claude-env
context env/human/claude-env
work .../.h5i/env/human/claude-env/work
next h5i env run claude-env -- <cmd> · h5i env shell claude-env · h5i env propose claude-env Drop into the box and let the agent off the leash safely:
$ h5i env shell claude-env
box$ claude --dangerously-skip-permissions
box$ exit Then review, propose, and apply, where the diff only lands on your branch if you say so:
$ h5i env diff claude-env
@@ -3,3 +3,6 @@ def add(a, b):
def sub(a, b):
return a - b
+
+def mul(a, b):
+ return a * b$ h5i env propose claude-env
$ h5i env apply claude-env The dangerous execution stayed contained. Only a reviewed diff crossed the boundary.
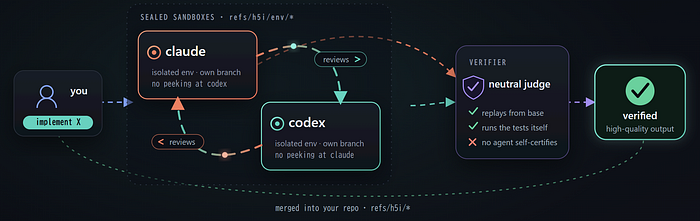
5. Run an ensemble
Independent attempts beat isolated guesses. Give the same task to two agents, each in its own sealed sandbox, let them peer-review each other, then a neutral verifier replays every candidate, runs the tests itself, and merges the one that actually passes.
Press enter or click to view image in full size
{kind=link}
Create two boxes and a team
$ h5i env create claude-env --profile agent-claude
$ h5i env create codex-env --profile agent-codex
$ h5i team create qsort-demo --base HEAD
$ h5i team add-env qsort-demo env/human/claude-env --runtime claude
$ h5i team add-env qsort-demo env/human/codex-env --runtime codex
$ h5i team status qsort-demo team qsort-demo (qsort-demo)
phase : draft
base : 1b7d294fa063
agents : 2
submits : 0
- milo working env/human/codex-env
- nina working env/human/claude-env
h5i assigns each agent a short, human-friendly key (`milo`, `nina`); note them, you'll use them at verify time.
Dispatch one task to everyone
$ echo "Implement Quick Sort from scratch in Python." | h5i team dispatch qsort-demo✔ dispatched to 2 agents Then launch each agent in its own sandboxed env, and each picks up the dispatched task automatically via `h5i team bootstrap`:
Terminal 1: Claude, inside its own h5i sandboxed env
$ h5i env shell env/human/claude-env -- claude --dangerously-skip-permissions "$(h5i team bootstrap)"# Terminal 2: Codex, inside its own h5i sandboxed env
$ h5i env shell env/human/codex-env -- codex --sandbox danger-full-access "$(h5i team bootstrap)"
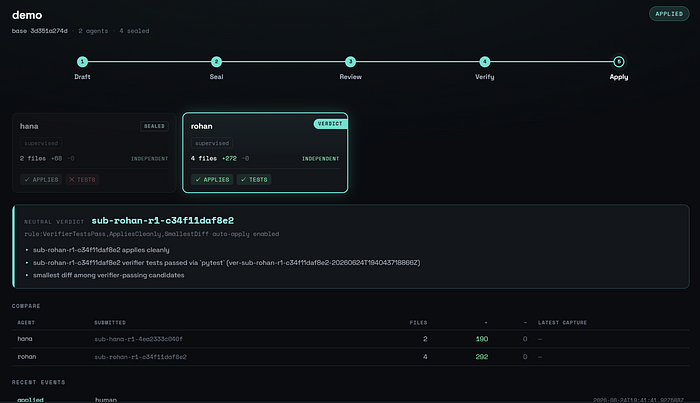
Peer-review, verify, merge the winner
Each agent works, peer-reviews the other’s submission read-only, and revises. Then the neutral verifier replays every candidate, runs the tests, and merges the winner:
$ h5i team auto-peer-review qsort-demo ✔ round 1 frozen · 2 candidates
granted nina → milo (read+diff) · milo → nina (read+diff)
review requests delivered to both agents$ h5i team verify qsort-demo --agent nina -- pytest ✔ verifier replayed candidate nina in a clean box
pytest · 6 passed in 0.04s (exit 0)
evidence recorded · refs/h5i/team/qsort-demo$ h5i team finalize qsort-demo ✔ verdict: nina
✓ tests passing (verifier-replayed) ✓ peer-review clean ✓ smallest passing diff
milo — rejected: 1 test failing under replay$ h5i team apply qsort-demo
Watch it live
$ h5i serve
Press enter or click to view image in full size
{kind=link}
What you get
Everything the run touched is recoverable later, without taking any agent’s word for it. Reviewers and follow-up agents pull the sidecar (`h5i share pull`) and read the provable record Git can't show by itself.
Per-line provenance — who wrote each line, with what prompt:
$ h5i recall blame calc.py STAT COMMIT AUTHOR/AGENT | CONTENT
prompt: "Add a sub(a,b) helper next to add()"
1b7d294f AI:claude-code | def add(a, b):
1b7d294f AI:claude-code | return a + b
1b7d294f AI:claude-code |
1b7d294f AI:claude-code | def sub(a, b):
1b7d294f AI:claude-code | return a - b Deterministic risk triage — no model in the loop, so review starts with the changes that need it most:
$ h5i audit review --limit 50 Suggested Review Points — 1 commit flagged (scanned 50, min_score=0.50)
──────────────────────────────────────────────────────────────
auth: refresh token rotation
⬦ SECURITY_SENSITIVE touches token / credential handling
⬦ API_TOKEN_LEAKAGE secret-shaped literal added
⬦ UNTESTED_CHANGE no test metrics recorded
db: migration for sessions table
⬦ LARGE_DIFF broad scope
⬦ LOW_PROMPT_CERTAINTY vague instruction
────────────────────────────────────────────────────────────── And the full provenance and context trail:
$ h5i recall log --limit 10
$ h5i recall context show --depth 2
The takeaway
The scarce resource is no longer code generation. It’s safe code acceptanc, and that’s exactly the layer h5i owns.
Coding agents generate patches. Sandboxes contain risky execution. Observability records what happened. h5i sits on top and decides _what is safe to merge_, with the evidence stored in Git.
Rule of thumb: wire the hooks once, sandbox every agent, run an ensemble when the task is worth more than one attempt, and let the neutral verifier pick the winner. Two heads really are better than one — and now both of them are on the record.
It all lives in your Git (`refs/h5i/*`). No SaaS, no lock-in, works offline.
$ curl -fsSL https://raw.githubusercontent.com/h5i-dev/h5i/main/install.sh | sh ★ github.com/h5i-dev/h5i · h5i.dev