The Expensive Fictions of Low-Level Programming Languages
I’ve been telling parts of the story of a future with trustworthy search processes that automate software development. If we have a clear and specific-enough formal specification to start out with, then recursive self-improvement can proceed in a way guaranteed to align with our goals. I talked through a number of reasons for optimism on that front, including lessons from recent use of formal verification (for connecting verified pieces together and anticipating new security threats) and speculating about changes in an economy dominated by AI agents (simplifying user interfaces and requirements gathering). The first point of informed skepticism about this idea is usually about the challenge of writing such specifications. There are still plenty of challenges left in assembling good specifications for highly capable systems, but let me now turn to further challenges, which apply after specifications are written.
Let’s consider in general the problem of automatic generation of code from its specification. Many AI coding assistants are being used today to write code in a “best effort” way, where the result may include mistakes such that the generated program does not follow its specification. I’m most interested (and future posts will most commonly discuss) methods that are _correct by construction_, where a tool might give up but will never return an incorrect program. An especially interesting approach is structured search through the space of programs, using formal verification as a fitness function to evaluate intermediate and final program variants.
Regardless of what approach is taken to automatic programming, we face conflicting desires to, on the one hand, _simplify the space of programs and how we reason about it automatically_; and, on the other hand, _generate the highest-quality programs in the end_. The rub is that higher-quality programs may be longer and more complicated than their lower-quality cousins, requiring more expensive search to find. An important determinant of the effectiveness of search is choice of programming language(s). My main claim in this post is that widely used programming languages are poorly suited for this style of search, especially when we are trying to write high-performance programs – which will be the case when we think about a program-search system recursively improving itself, given how much time and space a complex search can take. To argue this claim, I will start by spelling out a general framework for program search, and then I’ll draw attention to a missing ecological niche within that framework that is underserved by widely used programming languages.
Let me describe at a very high level a process of gradually refining a specification into a final program. Arguably, human software engineers work in this way, and we can expect to rely increasingly on programs that automate the process. There is a tradition in computer science that makes the ideas formal, called derivation by stepwise refinement, but I’ll leave things largely informal here. We can think of the exploration as moving from the top of the following schematic depiction to the bottom.

{kind=link}
The highest levels of the diagram deal with relatively abstract notation and therefore allow the most functionality to be covered by the shortest descriptions. The lowest levels are closer to the computer hardware we plan to run on, and they require details to be spelled out in excruciating detail.
Every node of this search is a program in some programming language. Every language we choose should pay off in tractability of search, control over details of the final program, or both. The most straightforward model is that we start off choosing languages biased toward simplifying search and eventually transition to languages that provide low-level control, though mixing the benefits throughout is also fine. Regardless, it should be a red flag if we are ever working with a language that scores poorly on both axes… yet I will claim that today, AI code generation is overwhelmingly working with such languages.
Let’s think in particular about languages suitable for the lower levels of the search process. A very dedicated software engineer might work directly with assembly language, almost the lowest-level form of programming undertaken today. However, it would be much more common to bottom out at a programming language like C), which was invented in the 1970s and has overwhelmingly influenced the design of low-level languages. More precisely, such languages are meant to allow fine-grained control over how a program uses available hardware resources and achieves the best performance.
There has been a lot of great innovation recently in this space of programming languages. Probably the biggest success story is the Rust language), which adds formal verification-style checking that programs follow safety rules. In contrast, C has been notorious for how easy it is for programmers to introduce mistakes that compromise safety and security. These safety rules don’t guarantee that a program does exactly what we want it to do, but formal-verification tools like Verus and Prusti add that kind of checking. As a formal-methods zealot myself, I won’t be satisified until some such verification method is considered to be part of the language definition, and programs that fail verification are considered ill-formed. However, for the rest of this post, I want to focus on a different axis of language design.
The problem is that languages in this category are meant to give fine-grained and effective control of performance. I would argue that higher-level languages are almost uniformly more pleasant to use to implement programs where performance doesn’t matter; we only choose a language like C or Rust to let us tune performance. Lisp machines provided a lovely stack for developing all code in a unified high-level language, and they “only” were missing performance capabilities, to keep up with other trends in hardware! The problem is that C was designed for the hardware of the 1970s and hasn’t been updated for the directions the computing world is heading in, with the end of Moore’s law forcing more cleverness in how we arrange computation. Thus, this language family is designed to fit snugly against the hardware model _of the 1970s_ but fails to expose the affordances needed to get good scalable performance today. C, Rust, and friends are _too low-level_ to be programmer-friendly high-level languages, and they are also _too high-level_ to expose the true toolbox of performance optimization. (If we are stuck with particular fixed hardware, then C and Rust may give programmers just about all the performance knobs they have available, but we should think bigger and codesign new hardware with its programming tools.)
Computer hardware has always mediated between the physical world and nice abstractions for programming, but that kind of “magic” mediation layer has had trouble scaling. The reality is that computation takes place in three-dimensional space, but let’s simplify down to two-dimensional space for purposes of this blog post (even though three-dimensional chip technologies are gaining in popularity). Then we have a sea of nodes spread through space, and let’s say each node stands for computation or storage.
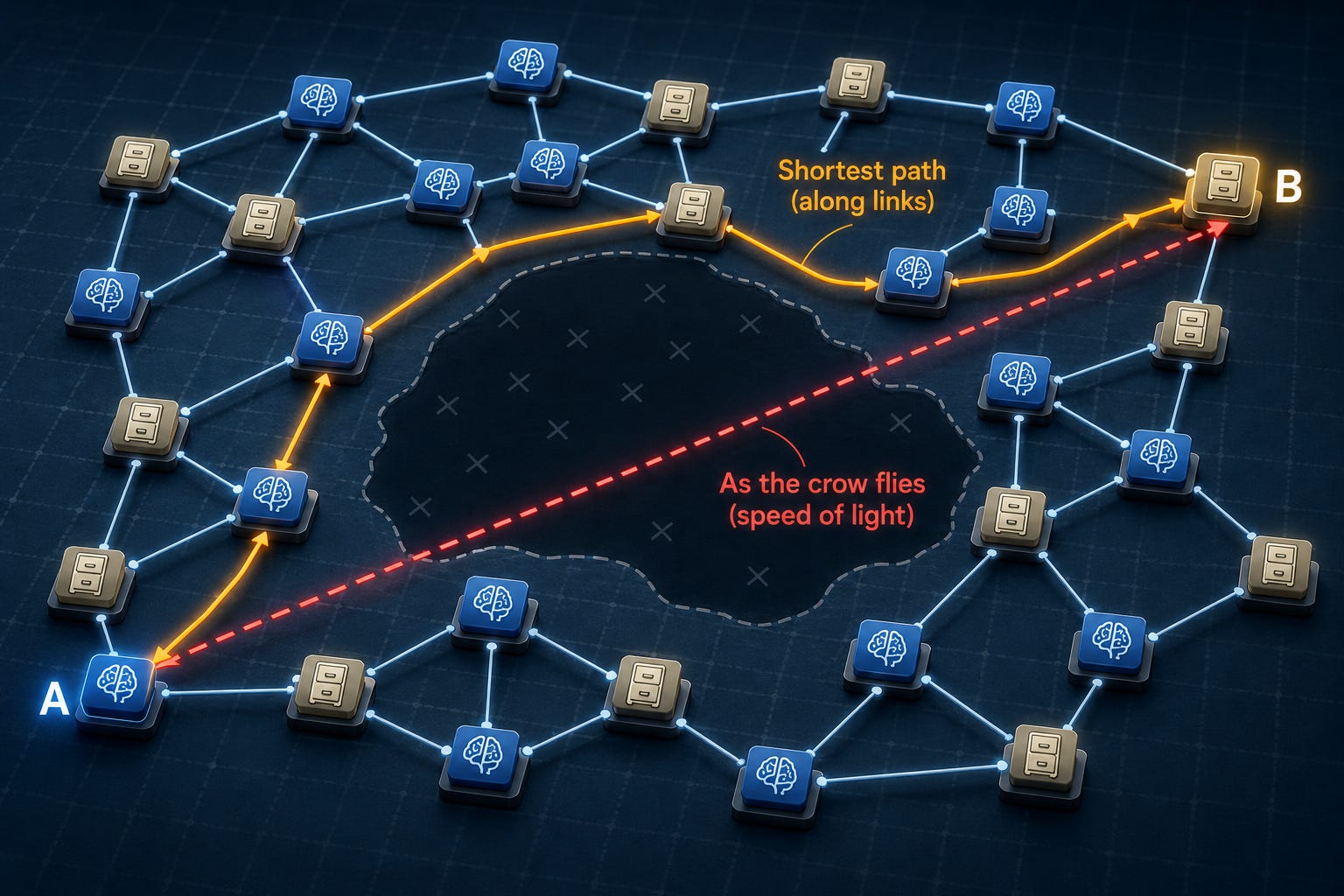
{kind=link}
Some pairs of nodes are connected by wires, and typically signals only propagate along those wires. (Wireless communication creates enough overhead to make it infeasible at the scale we’re talking about here.) Because there is a manufacturing cost per wire, relatively few of the potential direct connections between nodes are built out. As a result, the fastest path between two nodes may take a rather-indirect route, as opposed to the most direct geometric path down the middle of the picture. However, that direct path establishes a kind of fundamental speed limit for communication between a node pair, often called the “speed-of-light limit” when we assume a signal propagates at the maximum possible speed.
I discussed a simplified version of this kind of system earlier in the context of fundamental performance limitations of deep learning. There the point was that a deep-learning system can be seen as a computation graph (system of nodes and edges between them), with edges representing input-output relationships. Computing the final answer requires computing the values of all nodes, which will take _at least as long as the longest path that exists in the graph_, an important measure called _critical-path length_. As systems scale, the communication overhead of propagating signals along wires often comes to dominate total execution time, and **the major flaw in C, Rust, and their relatives is that the programming model hides these communication overheads and the aspects of program structure that make them tractable to predict and control**.
Conventional low-level programming lives in a fantasy world that deviates from reality in two major ways. These big two were also presented in Chisnall’s “C Is Not a Low-level Language”, and the additional point that I’m emphasizing is that these fantasies make it harder to evaluate the performance of a program, which makes effective program search harder.
1. _We pretend code looks like sequences of instructions that run one-at-a-time._ In reality, all parts of a physical computation fabric are always “running.” Hardware like CPUs tries hard to promote _utilization_, the fraction of nodes doing useful work at some instant, but it can only go so far, reverse-engineering the structure of fundamentally _sequential_ code even when the related behavioral questions are undecidable.
2. _We pretend that there is one big shared memory that all parts of a program access._ Yes, this abstraction is painstakingly constructed by hardware, but we can’t think of it with a naive _cost model_. The time to access a memory location at a particular computation node can vary dramatically based on a variety of factors, and the same node can experience very different access times for the same memory location at different moments. The principles behind predicting these performance factors come down to tracking locality of memory references, a concept that unfortunately often requires _global_ thinking, meaning understanding the performance of one part of a system can require tracking behavior of other parts in detail. Alternatively, we can use established abstractions like MPI that reveal the hardware topology more directly, but these systems are also seen as painfully low-level and difficult to program.
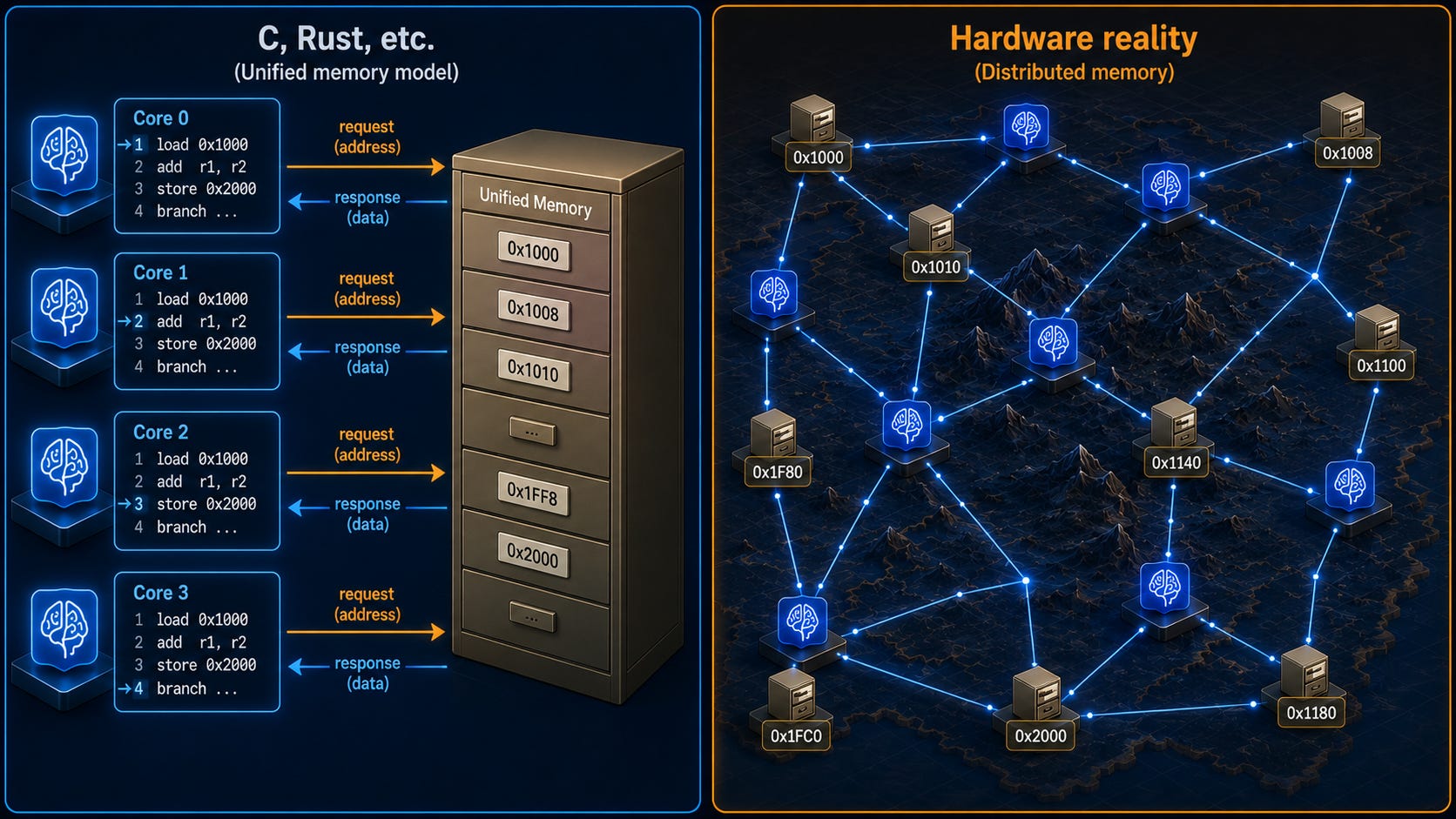
{kind=link}
An abstraction of sequential code execution is helpful for puny human brains to keep up in understanding a program, but it’s just too far from reality to be ideal for analyzing scalable performance. Low-level programming languages have usually started from sequential programming features and provided bolt-on features to explain how several such programs should run at once. The inability of language implementations to understand what is happening within the units of parallelism makes it harder to perform significant code rearrangements automatically as optimizations.
The most elite performance engineers can keep the organizations of specific hardware platforms in mind, to look at conventional software programs and “see” what they will cost to run. However, the details are punitively complex, which holds back automatic search through program variants to find the ones with the best performance. Importantly, this level of performance modeling seems to require thinking about programs at a very low level of abstraction that hides very little about hardware organization. At that level of abstraction, even simple-sounding improvements can require changes to many lines of code, perhaps spread across a large code base, and many search heuristics can never pull off that level of synchronized modification. (An example of such a nonlocal modification is dropping in a new data structure that requires a new coordination protocol for shared-memory accesses by all parts of the code touching the data structure.)
Whether we are thinking about human software engineers designing and implementing a program or about AI search through a space of programs realizing a specification, two properties are especially helpful in the notations we use to represent programs under consideration. Some notations allow us to describe complex systems succinctly, and those notations are convenient to understand and manipulate algebraically. Some notations give us the control to describe every last detail of harnessing hardware for maximum performance. The trouble with mainstream programming languages like C and Rust is that they display major shortcomings with respect to both goals. Even partisans of those languages typically agree that programming simplicity is sacrificed for control, making automated understanding of programs and their behavior (performance-wise or otherwise) formally impossible, though additional structural disciplines like Rust’s can help. But then the performance model of code is only implicit, given the massive gap between the realities of hardware and the fictions of parts of a program running sequential code and accessing a shared global memory.
There are enough parts of this argument and its evidence and consequences that I’ll continue over the next three posts. First, I’ll explain the heroic effort of modern CPUs to present the C-style programming abstraction while exhibiting very opaque performance behavior. Next, I’ll suggest a convergence between the programming styles of software and hardware as a unifying principle to chart a better course. Finally, I’ll cover GPUs as an example of an approach that has evolved closer to this ideal but retains some real weaknesses relevant to creating trustworthy decision systems, the overarching topic of this blog. Setting the stage with these details will prepare us for more exploration of our overall slogan that “intelligence depends on organizing computation correctly and efficiently.”