GPT-5.5: Capabilities and Reactions
The system card for GPT-5.5 mostly told us what we expected. See this thread from Drake Thomas for some comparisons to Anthropic’s model card for Opus 4.7.
Now we move on to asking what it means in practice, and in what situations GPT-5.5 should become our new weapon of choice.
My answer is for some purposes yes, and for others no, but it is now competitive. GPT-5.5 is like GPT-5.4, only more so, and with improved capabilities in particular on raw intelligence and for well-specified coding and agent tasks, including computer use.
This is the first time since Claude Opus 4.5 came out, so in about four months, that I’ve considered a non-Anthropic model a competitive choice outside of some narrow tasks like web search. GPT-5.5 is not perfect, nor is it the best at everything, but basically everyone thinks this is a solid upgrade. Highly positive overall feedback.
My effective usage is now split between the two, depending on the nature of the task. If it’s something that can be well-specified and all I want is the right answer, my instinct is I go with GPT-5.5. If I’m not sure what exactly I want, or I want to have a conversation, or I want to do Claude Code shaped things, I go with Opus 4.7.
As always, try the models, test your use cases, and see what you think.
OpenAI reports this is a new base model, codenamed Spud, and predicts rapid iteration from here. One wonders if that means this move was a relatively large raw intelligence boost, whereas the next few iterations will be about functionality.
Price is $5/$30 per million tokens, or for Pro you pay $30/$180. OpenAI says that token use is more efficient now, so the headline price went up but real costs went down.

{kind=link}
The focus is on using your computer, coding, research and getting work done.
They’re also claiming a ‘much higher’ level of intelligence versus GPT-5.4.
As always, listen to the pitch, hear what they say and also what they don’t say.
> OpenAI: We’re releasing GPT‑5.5, our smartest and most intuitive to use model yet, and the next step toward a new way of getting work done on a computer. > >
> GPT‑5.5 understands what you’re trying to do faster and can carry more of the work itself. It excels at writing and debugging code, researching online, analyzing data, creating documents and spreadsheets, operating software, and moving across tools until a task is finished. Instead of carefully managing every step, you can give GPT‑5.5 a messy, multi-part task and trust it to plan, use tools, check its work, navigate through ambiguity, and keep going. > >
> The gains are especially strong in agentic coding, computer use, knowledge work, and early scientific research—areas where progress depends on reasoning across context and taking action over time. GPT‑5.5 delivers this step up in intelligence without compromising on speed: larger, more capable models are often slower to serve, but GPT‑5.5 matches GPT‑5.4 per-token latency in real-world serving, while performing at a much higher level of intelligence. It also uses significantly fewer tokens to complete the same Codex tasks, making it more efficient as well as more capable. > > > We are releasing GPT‑5.5 with our strongest set of safeguards to date, designed to reduce misuse while preserving access for beneficial work. > >
> Greg Brockman (President OpenAI): Codex + 5.5 is incredible for the full spectrum of computer use. No longer just for coders, but for anyone who does computer work (including creating spreadsheets, slides, etc). > >
> roon (OpenAI): there are early signs of 5.5 being a competent ai research partner. several researchers let 5.5 run variations of experiments overnight given only a high level algorithmic idea, wake up to find completed sweep dashboards and samples, never having touched code or a terminal at all. > > > Sam Altman (CEO OpenAI): GPT-5.5 is here! We hope it's useful to you. I personally like it. > > > It is smart and fast; per-token speed matches 5.4 and it uses significantly fewer tokens per task. In my experience, it "gets what to do". > > > API pricing will be $5 per 1 million input tokens and $30 per 1 million output tokens, with a 1 million context window. > > > (Remember, you will need less tokens per task than 5.4!) > > >
> Sam Altman (CEO OpenAI): 1. We believe in iterative deployment; although GPT-5.5 is already a smart model, we expect rapid improvements. Iterative deployment is a big part of our safety strategy; we believe the world will be best equipped to win at the team sport of AI resilience this way. > >
> 2. We believe in democratization. We want people to be able to use lots of AI; we aim to have the most efficient models, the most efficient inference stack, and the most compute. We want our users to have access to the best technology and for everyone to have equal opportunity. We have been tracking cybersecurity as a preparedness category for a long time, and have built mitigations we believe in that enable us to make capable models broadly available. > >
> 3. We love you and we want you to win. We want to be a platform for every company, scientist, entrepreneur, and person. (My whole career has largely been about the magic of startups, and I think we are about to see that magic at hyperscale.) > >
> Derya Unutmaz, MD: I’d been part of OpenAI early tester group for GPT-5.5. I believe with GPT-5.5 Pro we reached another inflection point-comparable to the original release of o1-preview & then with 5.0 Pro, I had felt. It’s that feeling of crossing a milestone threshold that pushes us to new era.
I note that is mostly general ‘campaign-style’ applause lights from Altman, and that we don’t see anyone actually saying a form of ‘introducing the world’s most powerful model’ even if you (reasonably, for practical purposes) exclude Mythos.
The argument is, it is an improvement, you get better results with fewer tokens.
> Tae Kim: “Yes, we expect quite rapid continued progress. We see pretty significant improvements in the short term, extremely significant improvements in the medium term,” OpenAI Chief Scientist Jakub Pachocki said on the call with reporters. “I would definitely expect that we will continue to see the pace of AI capabilities improvement to keep increasing. I would say the last few years have been surprisingly slow.”
It seems highly reasonable to call practical progress ‘surprisingly slow’ over the last few years, and yes the current expectation should be for it to go faster.
GPT-5.5 is now $5/$30 per million (and a lot more for Pro), versus $5/$25 for Opus 4.7.
For a long time, Opus was more expensive. Now this has somewhat reversed.
I offer three notes here.
1. OpenAI says 5.5 is more token efficient than 5.4.
2. What matters is tasks, not token count. It’s not obvious which is really cheaper.
3. The gap is small, use whichever you think is the better model.
The initial chart is a bit sparse but they add more things later.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
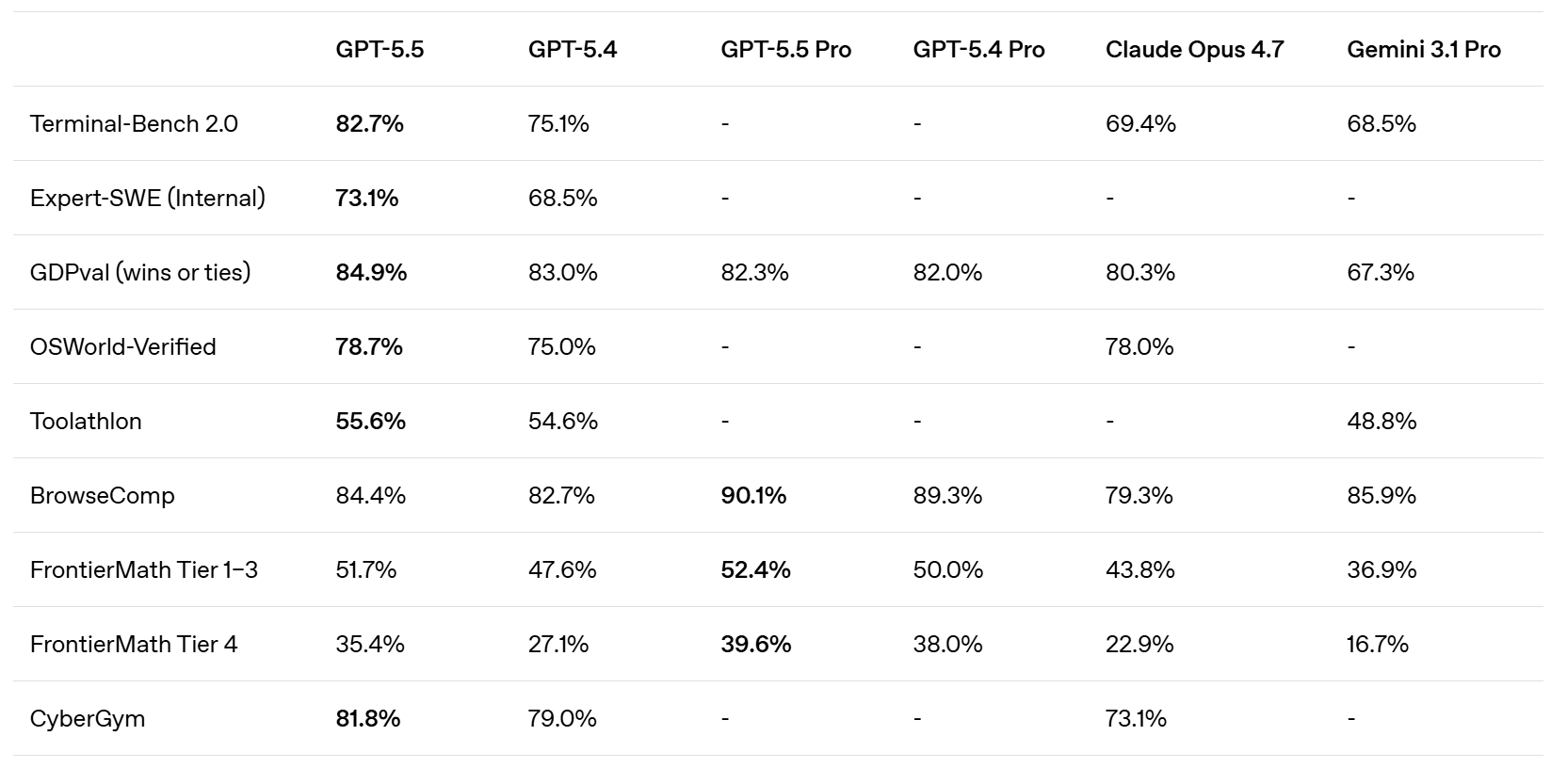
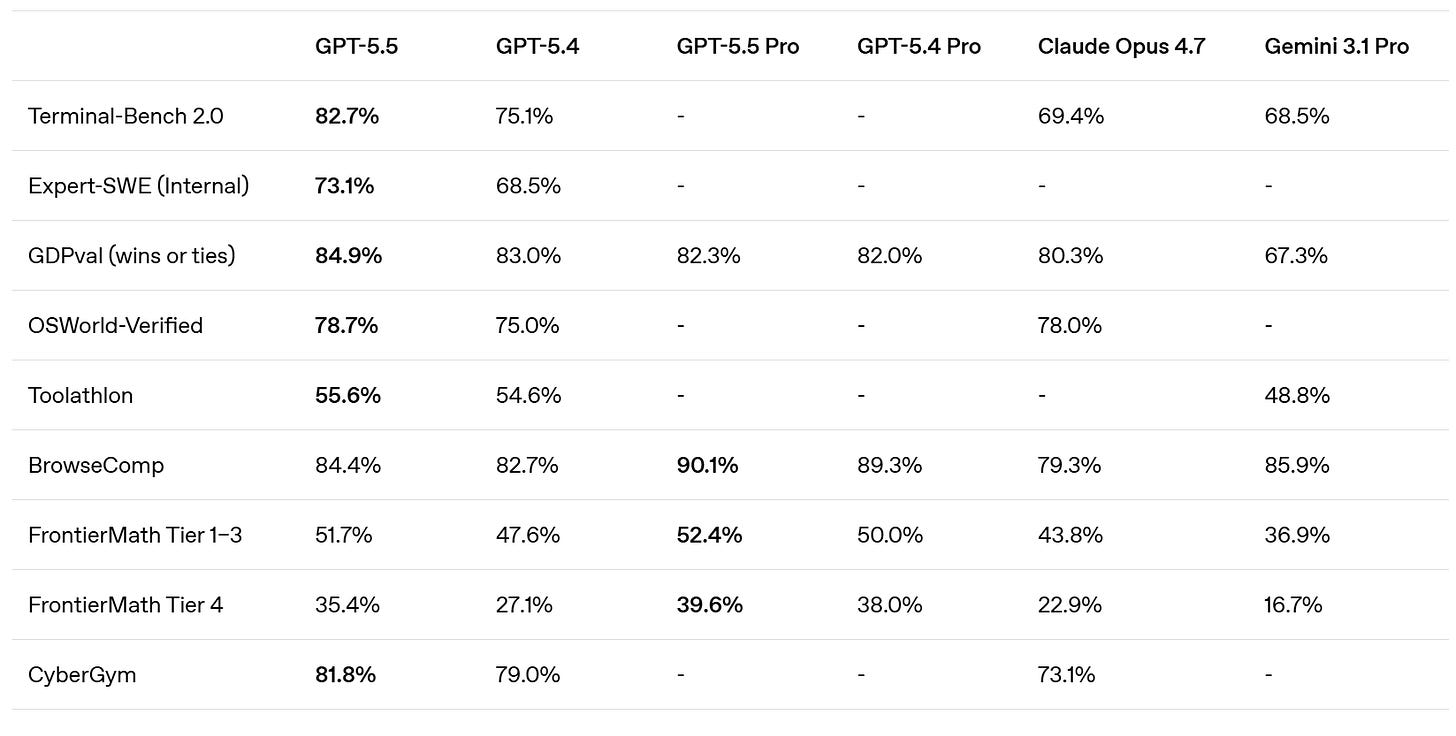
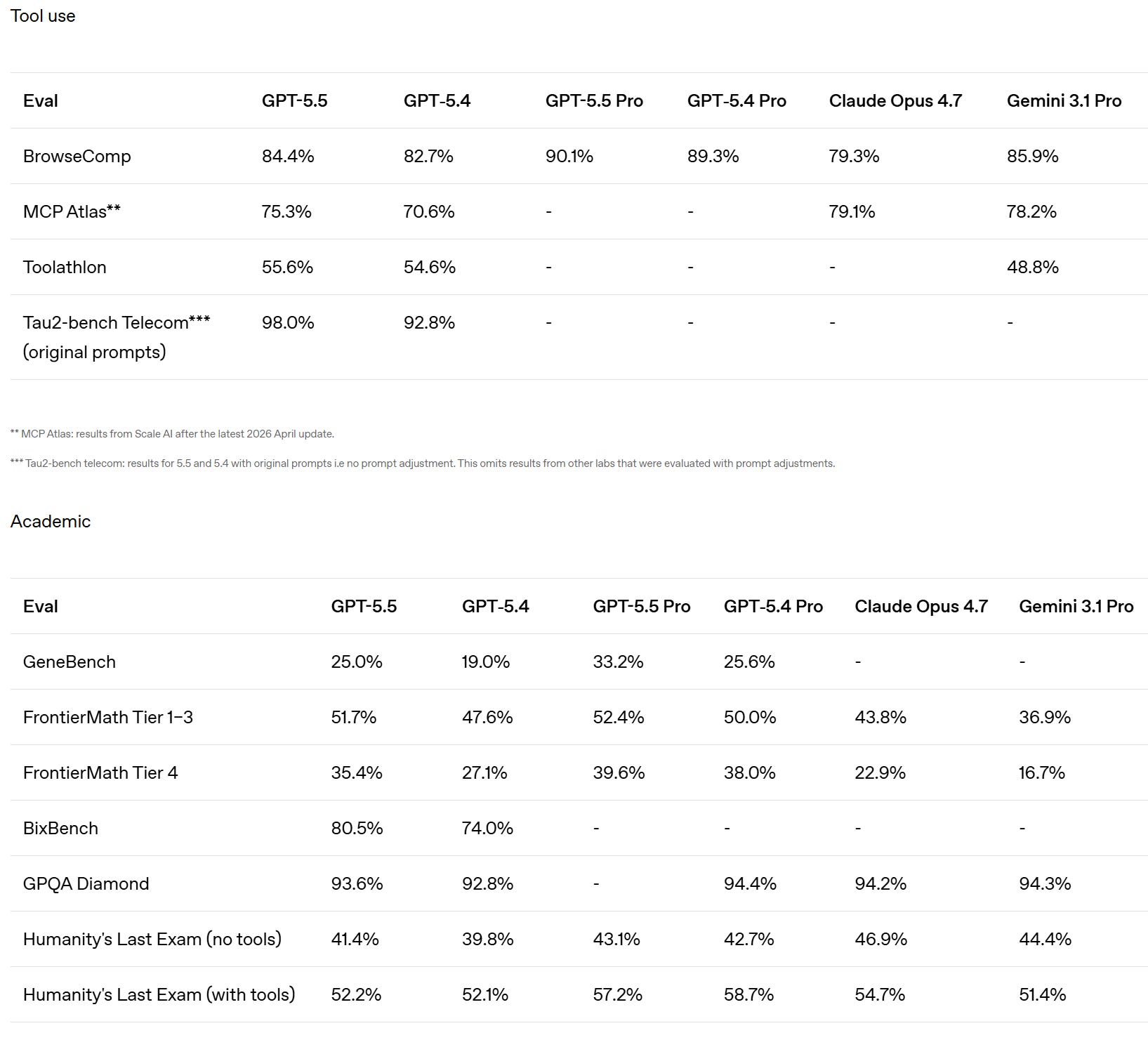
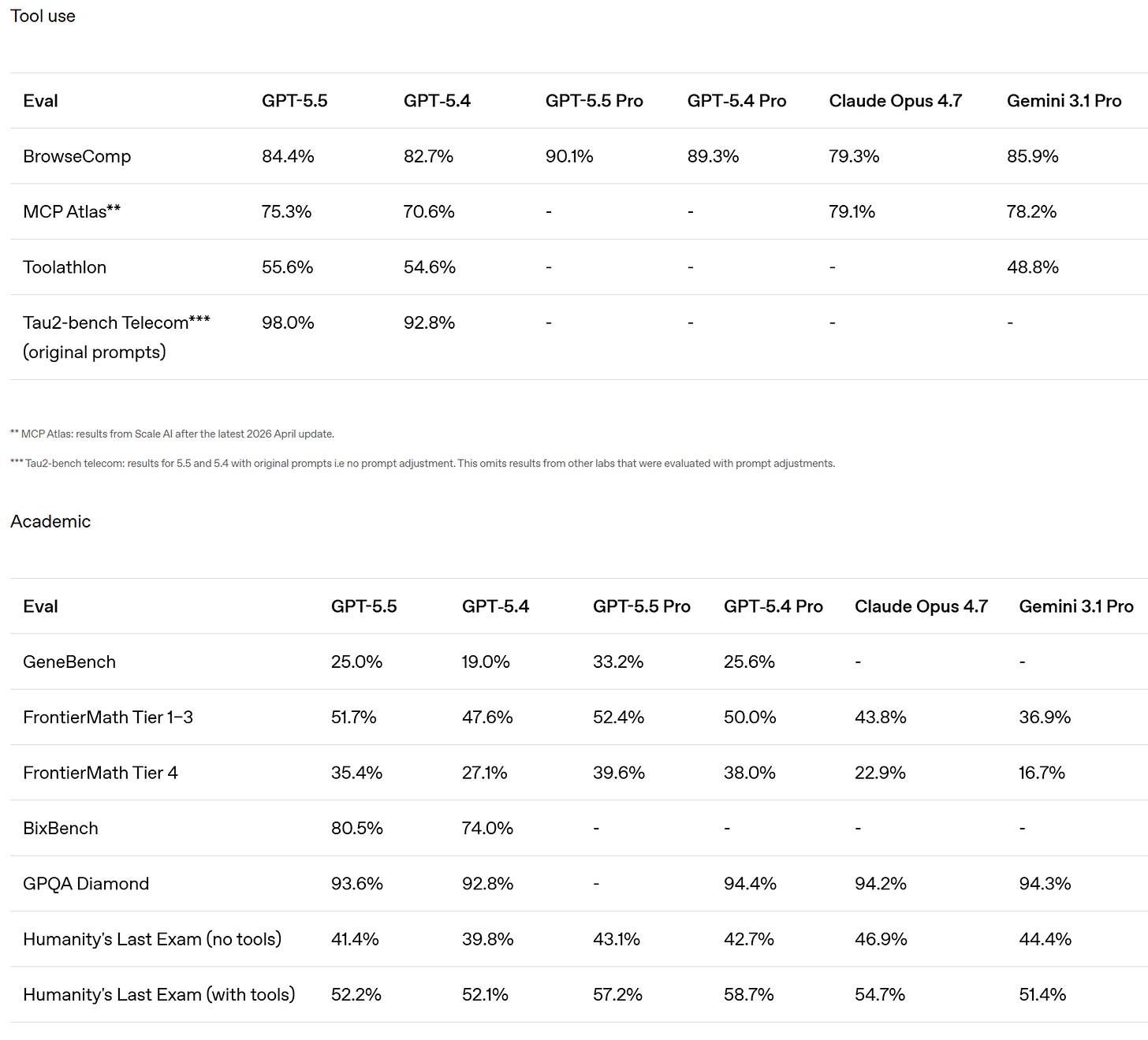
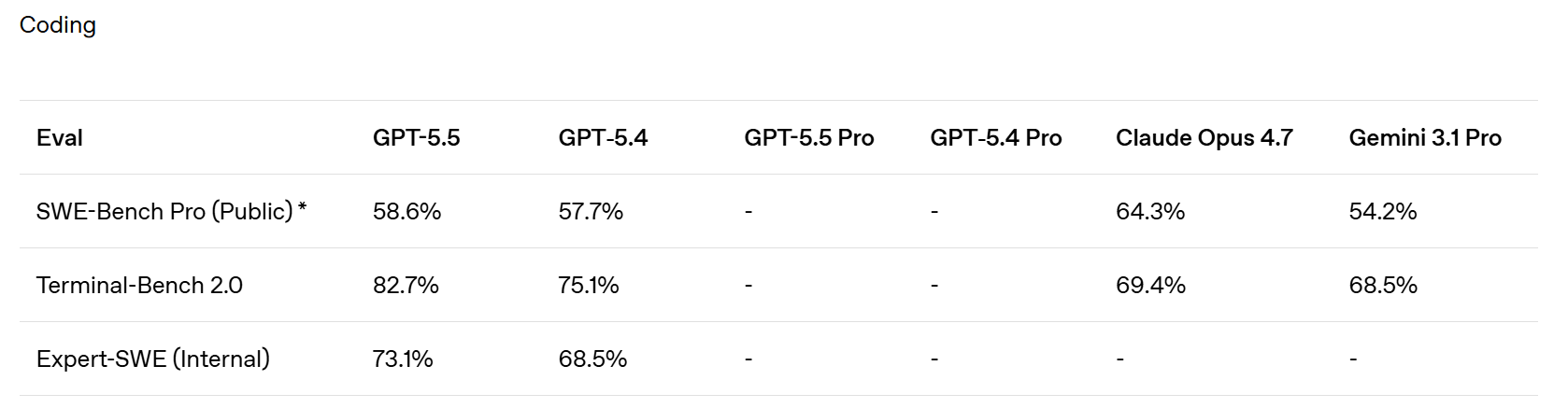
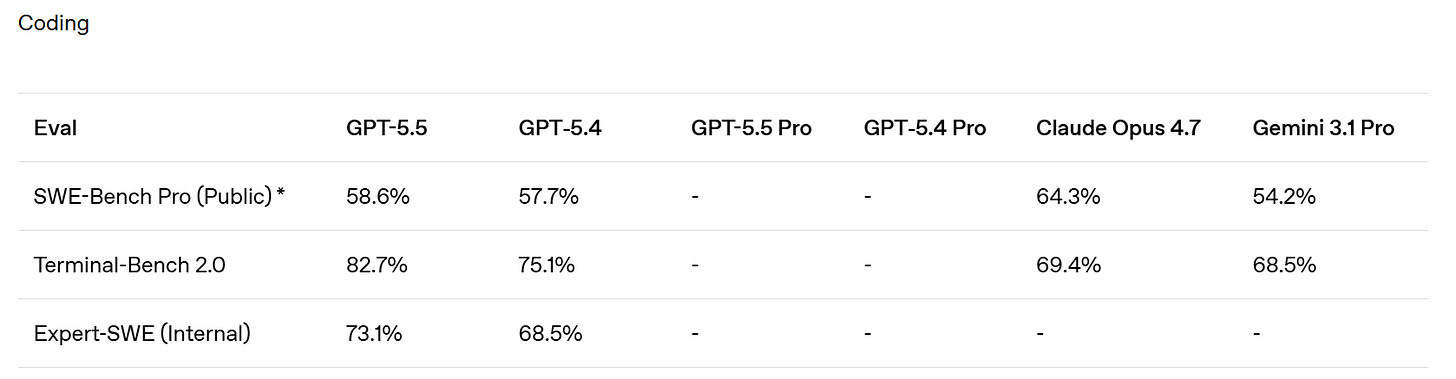
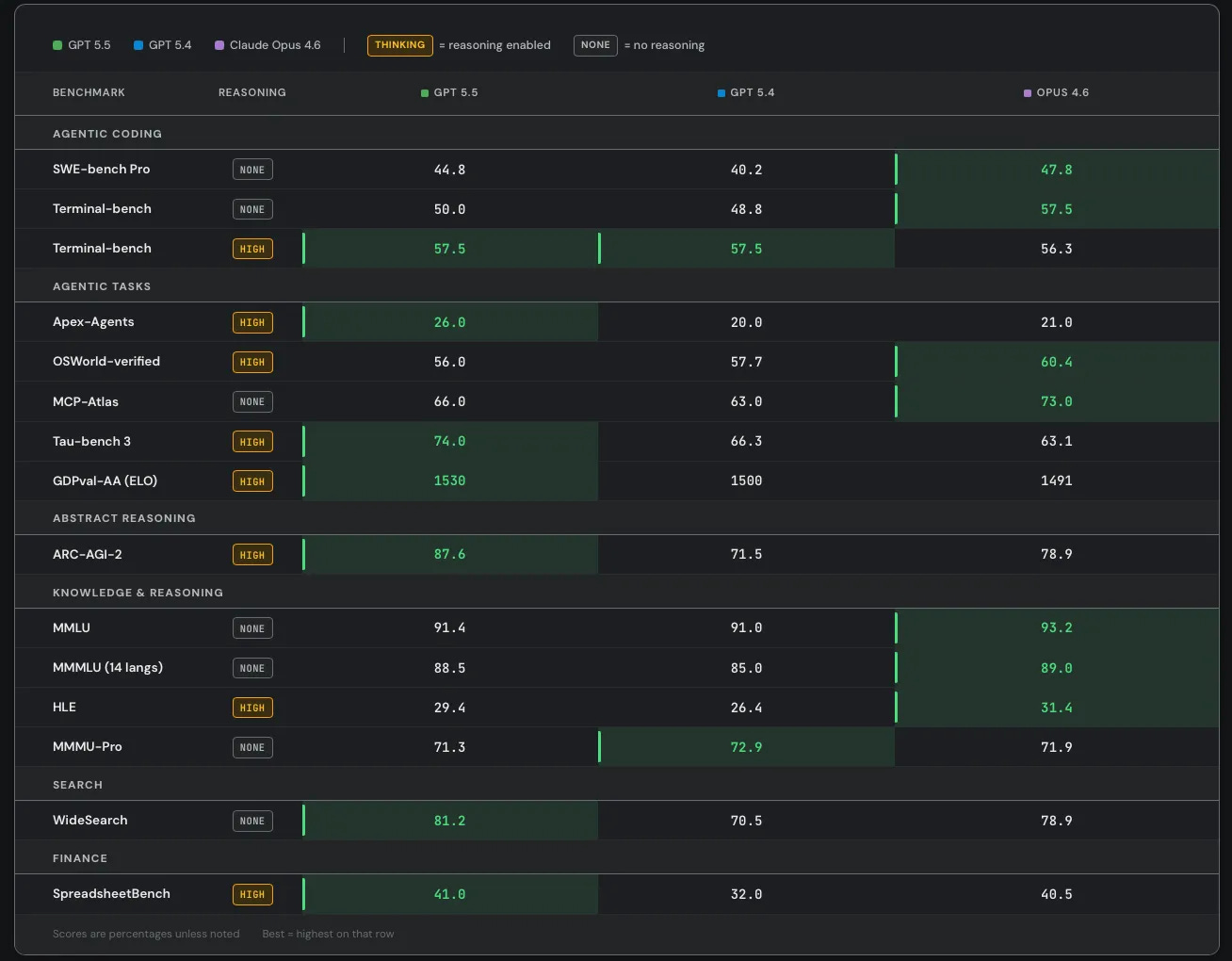
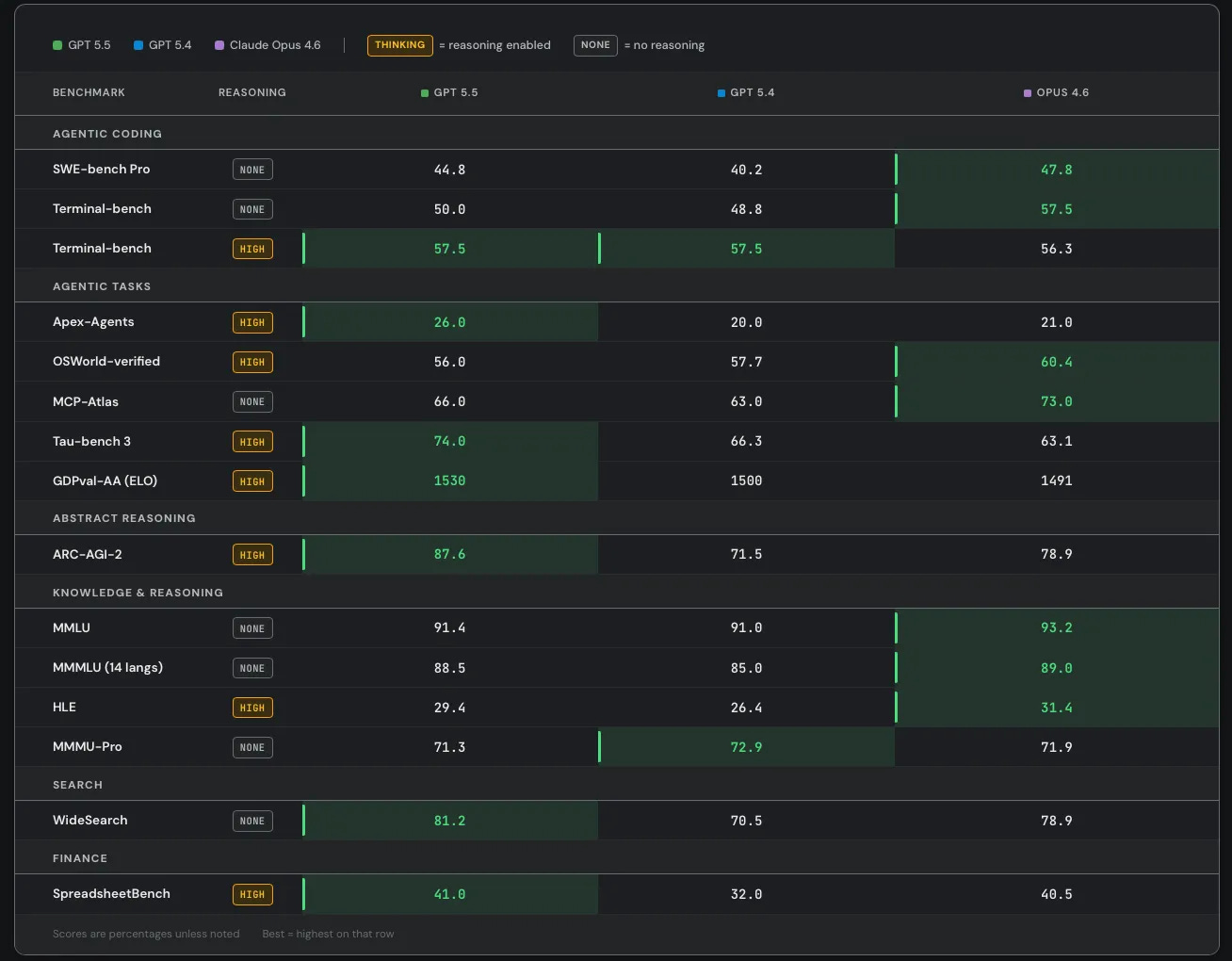
SemiAnalysis notes that SWE-Bench Pro got kind of buried here in favor of the ‘kind of random’ internal Expert-SWE, and suggests that is because GPT-5.5 did badly here? Mythos scores 77.8% on SWE-Bench Pro.
{kind=link}
There is also improvement on GeneBench and BixBench.
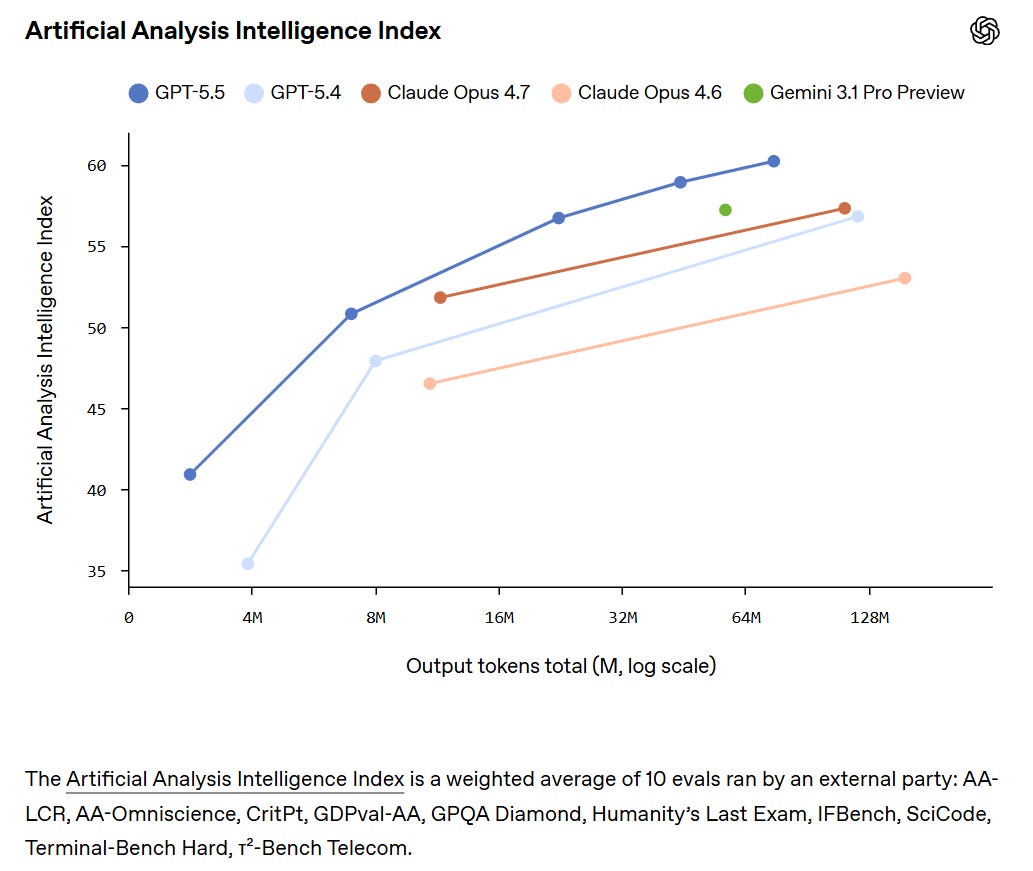
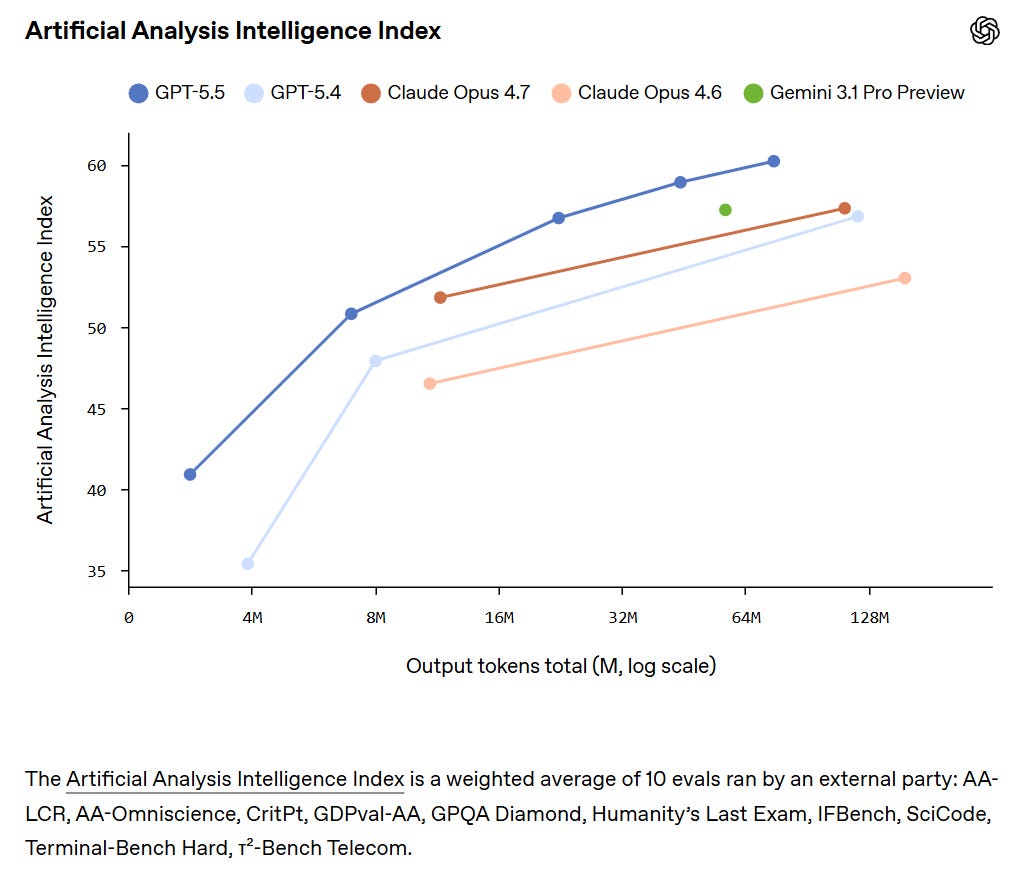
They claim superiority in the Artificial Analysis Intelligence Index, and better performance for any given number of tokens on Terminal-Bench 2.0 and Expert SWE.
{kind=link}
Cline confirms the Terminal-Bench score of 82.7%, which is even higher than Mythos at 82%. Up to some level of complexity GPT-5.5 can be highly competitive.
Codex, like Claude Code, is now ‘the real’ way to use the models to do work.
> When combined with Codex’s computer use skills, GPT‑5.5 brings us closer to the feeling that the model can actually use the computer with you: seeing what’s on screen, clicking, typing, navigating interfaces, and moving across tools with precision.
{kind=link}
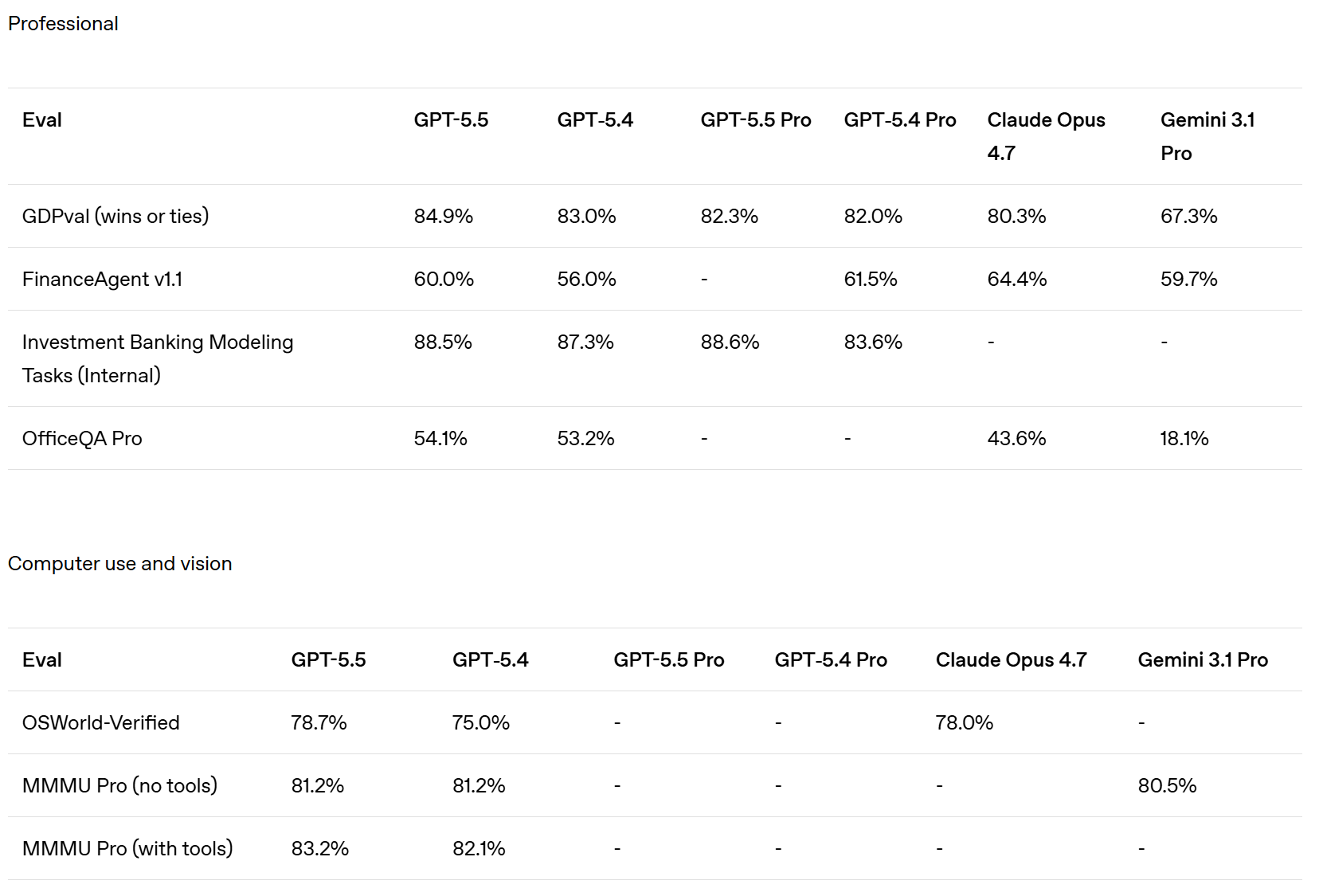
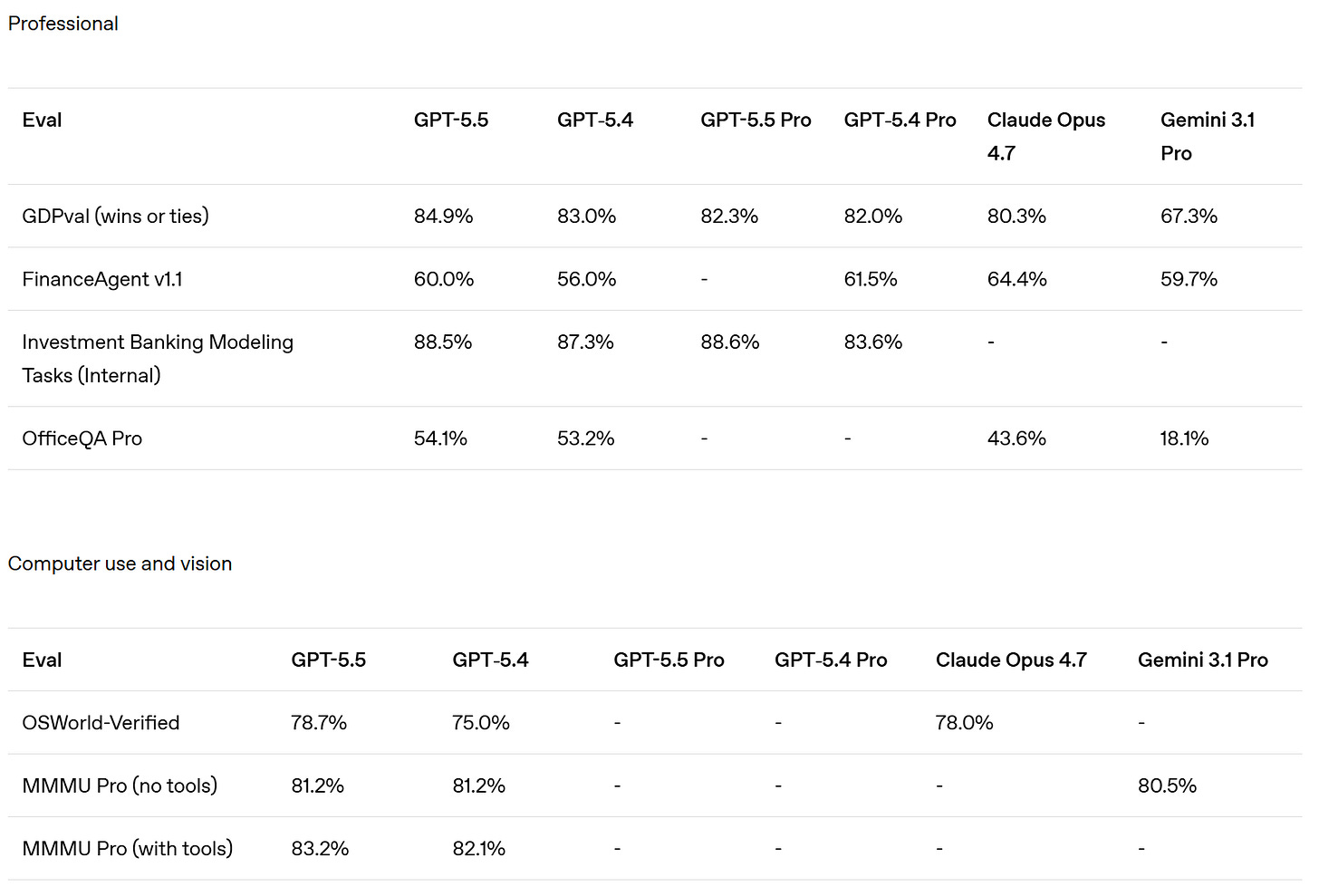
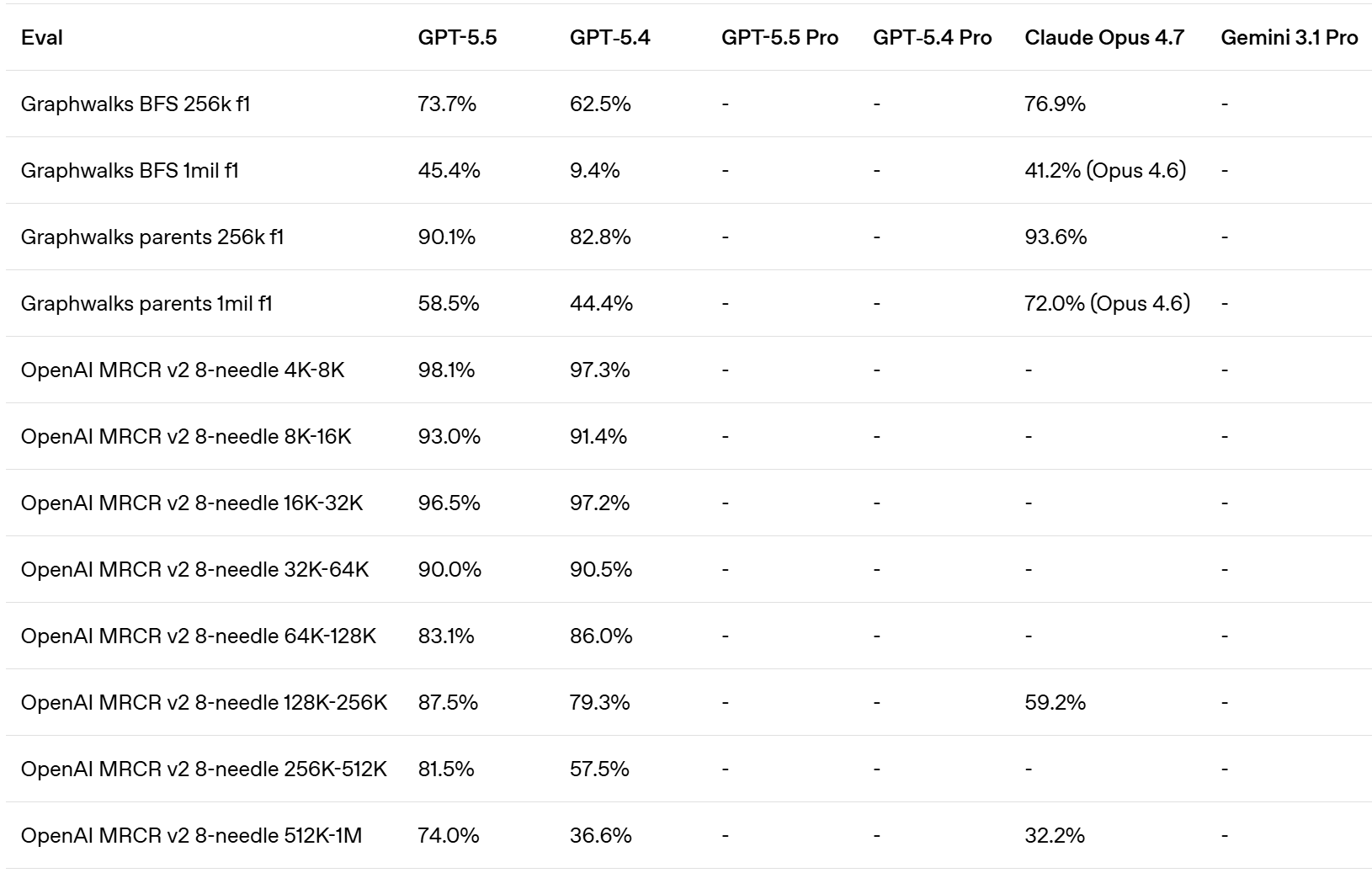
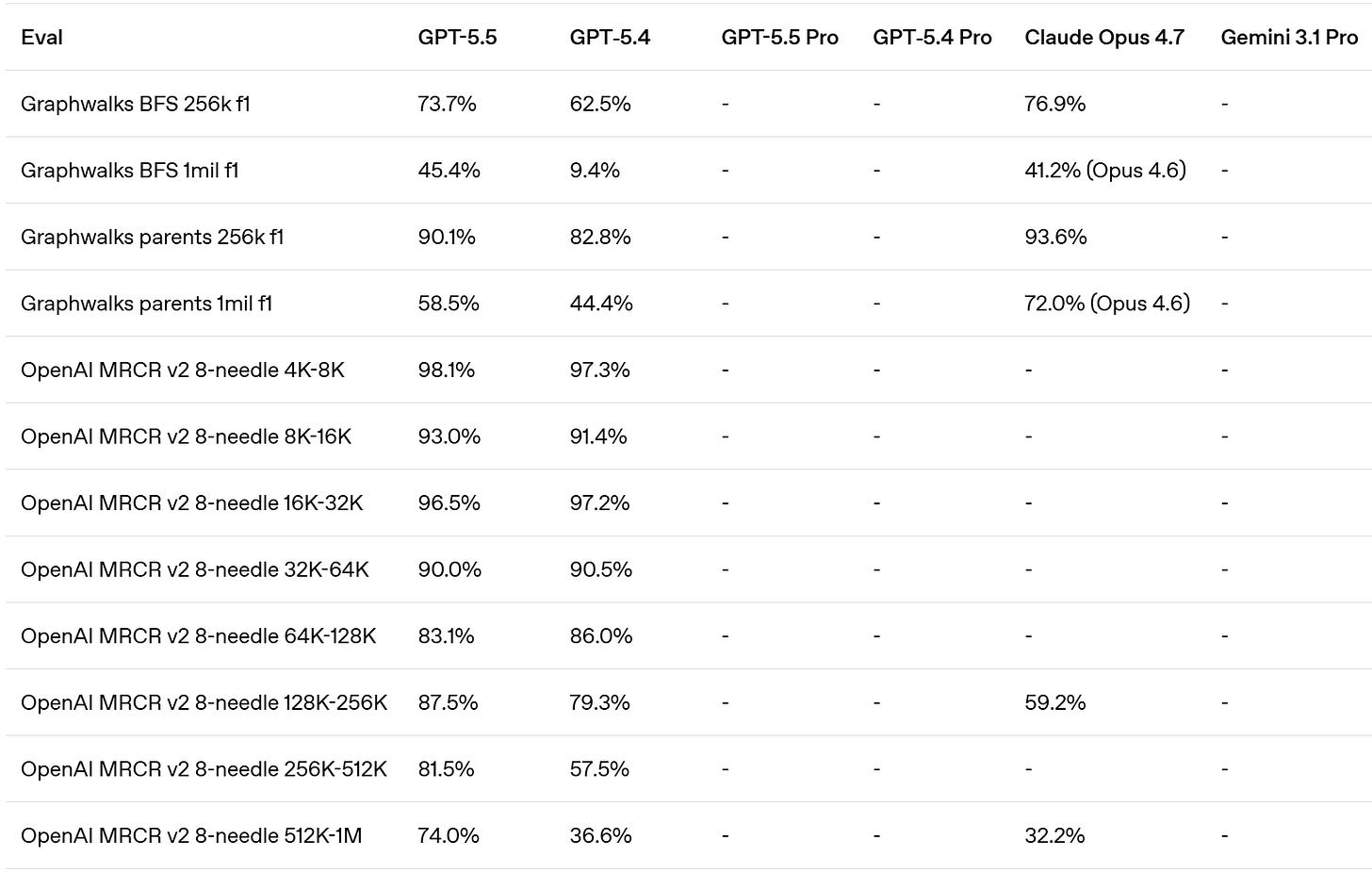
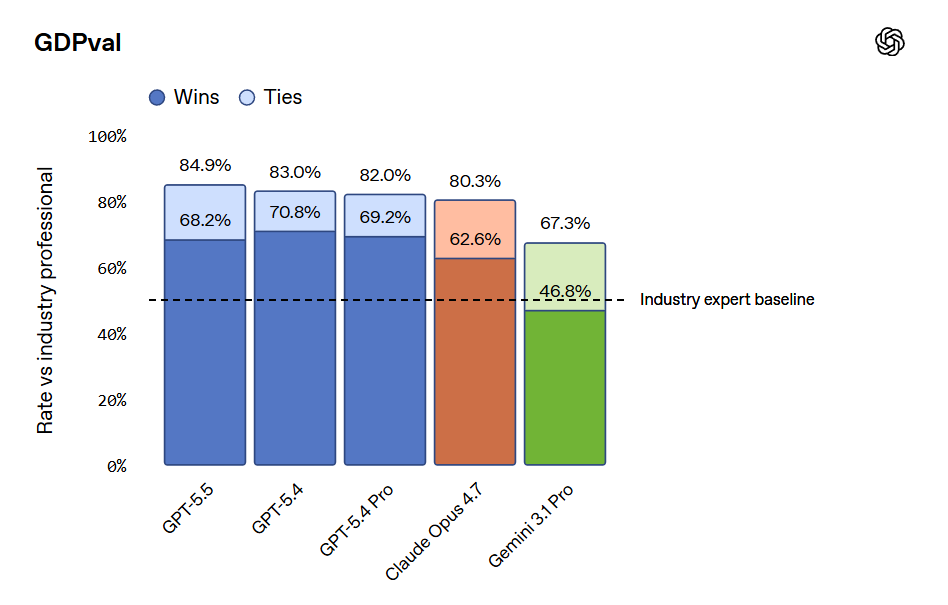
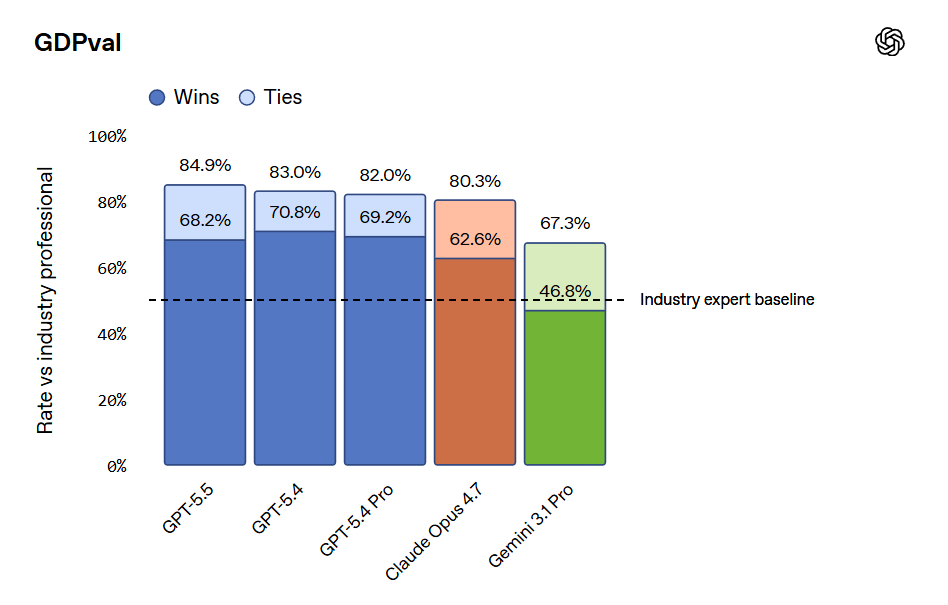
Whereas OpenAI claim that Opus 4.7 was already behind GPT-5.4 on GDPVal, although the GDPVal-AA scores showed the opposite by a healthy margin (1753 vs. 1674), with GPT-5.5 coming in at 1782 for xhigh and 1758 for high.
Presumably OpenAI ran the GDPVal tests itself, and also used win rates versus a human which stop being a great metric in the 80s. Here we also see a regression in full win rate (e.g. if ties count half) from 5.4 to 5.5. My suspicion is GDPVal is getting close to saturated, in that the remaining gap is largely about noise and quirky preferences, as in it’s about taste and taste varies a lot when humans are judging? So comparing ‘versus human’ becomes no longer interesting.
They compared to Opus 4.6, since they had early access to GPT-5.5 but not Opus 4.7. They note they used non-ideal harnesses and only ran subsets on some tasks, which explains the lower overall scores. This could be seen as more apples-to-apples, with GPT-5.5 and Opus 4.6 basically fighting to an overall draw.
{kind=link}
Artificial Analysis Intelligence has GPT-5.5 in a clear lead at 60, versus 57 for all of Opus 4.7, Gemini 3.1 Pro and GPT-5.4.
GPT-5.5 has a +20 in AA-Omniscience, in third behind Gemini 3.1 Pro and Opus 4.7.
GPT-5.5 has a small lead in GPTval-AA at 1780 versus 1753 for Opus 4.7.
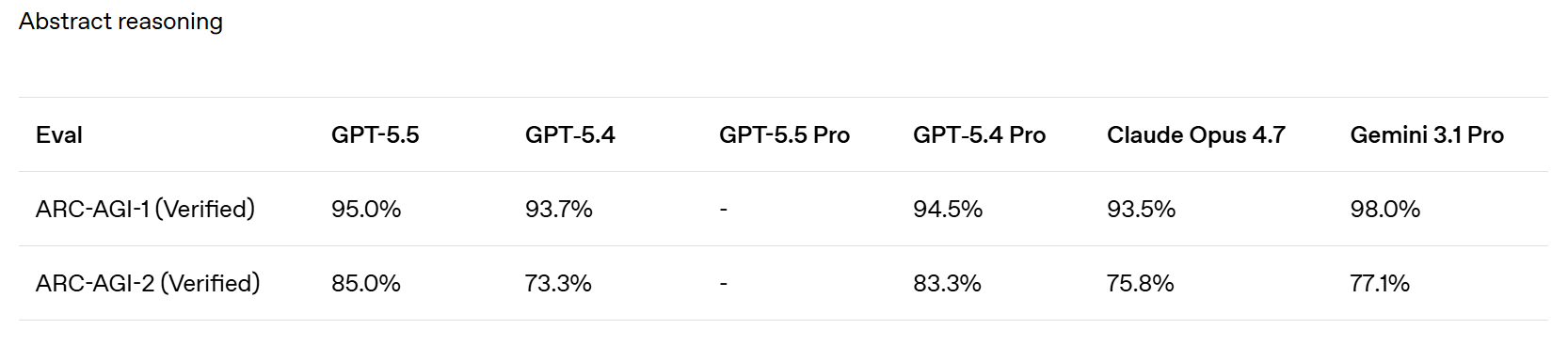
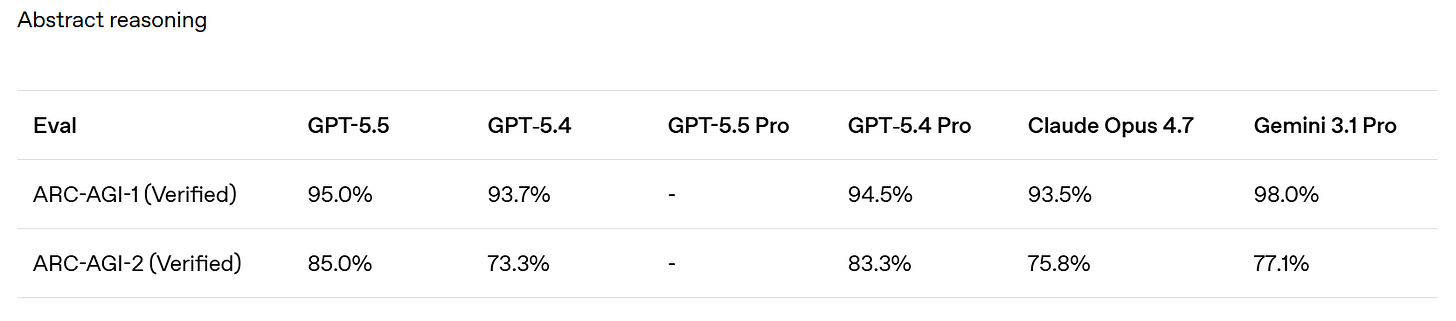
GPT-5.5 is SoTA on ARC-AGI 1 and 2. I don’t see results yet for 3.
> ARC Prize: GPT-5.5 on ARC-AGI (Verified) > > > ARC-AGI-2: > > - Max: 85.0%, $1.87 > > - High: 83.3%, $1.45 > > - Med: 70.4%, $0.86 > > - Low: 33%, $0.35 > > > GPT-5.5 is now state of the art on ARC-AGI-2 > > > ARC Prize: ARC-AGI-1: > > - Max: 95.0%, $0.73 > > - High: 94.5%, $0.56 > > - Med: 92.2%, $0.39 > > - Low: 76.2%, $0.20
GPT-5.5 scores 67.1% on WeirdML, well short of Opus 4.7 at 76.4%, but ahead of GPT-5.4 at 57.4%. Note that no one here is allowed to think.
GPT-5.5 is the new champion of the Runescape benchmark, although also the most expensive. Gemini Flash continues to impress here given its low cost.
Claude remains king at BullshitBench, GPT-5.5 is not a step up from GPT-5.4.
It’s a deeply silly test, as evidenced by Grok previously scoring 144, but GPT-5.5-Pro Vision is first to score 145 on Mensa Norway.
GPT-5.5-xhigh gets the new high of 10% for pass^5 on visual test ZeroBench (versus 4% for Opus 4.7 and 8% for GPT-5.4), but doesn’t gain on pass@5 (22% vs. 23% for GPT-5.4, and 14% for Opus-4.7). Gemini continues to outperform Claude here, as 4.7 is an improvement but Claude is still behind on vision.
Code Arena has GPT-5.5-High in 9th, a solid 50 point improvement over GPT-5.4, with Claude taking the top spots. GPT-5.5 did better in other areas, with a high of 2nd in search, with Claude generally dominant.
The exceptions are images, where OpenAI dominates, and video generation.
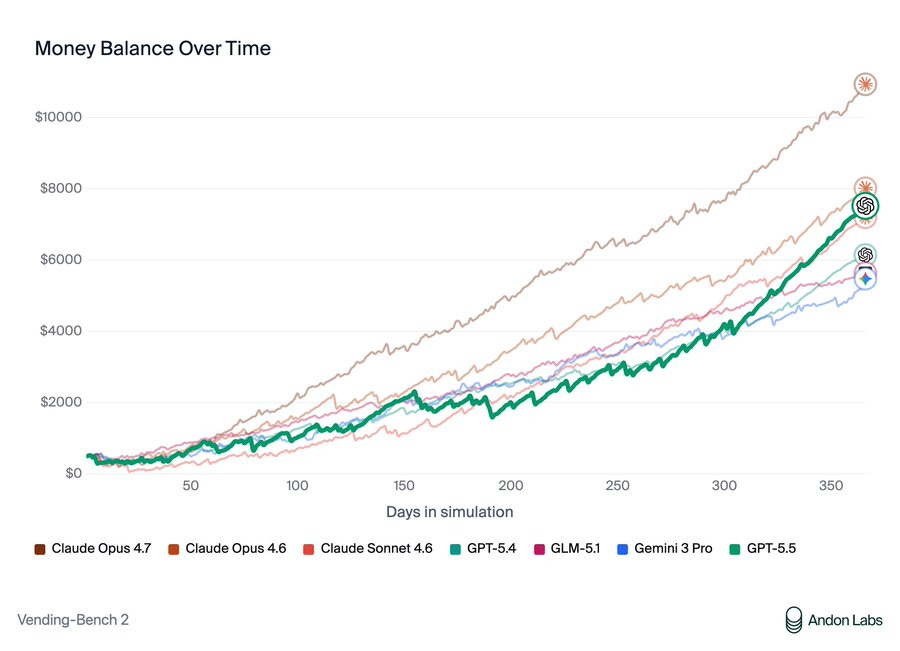
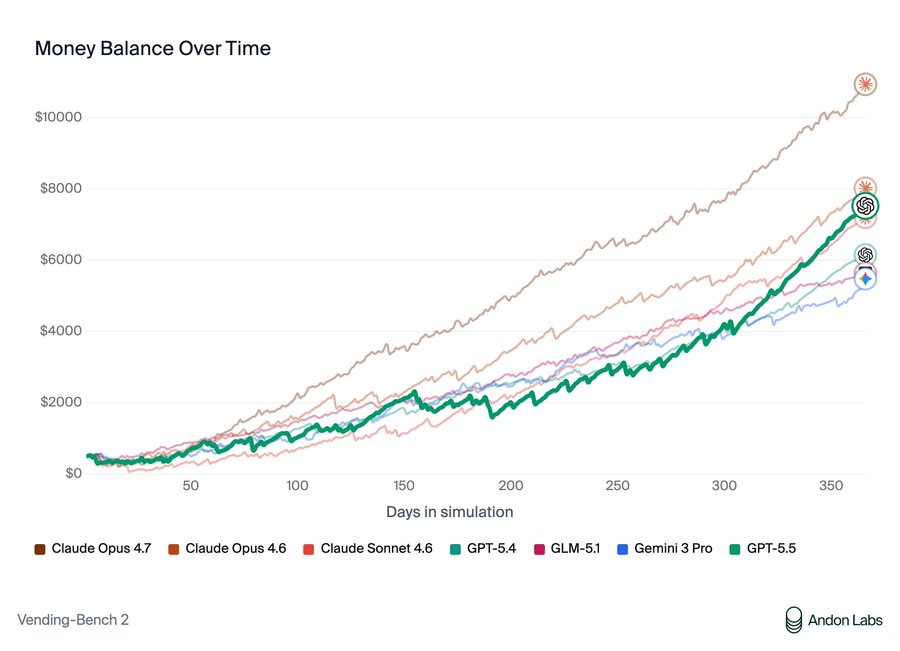
Opus 4.7 remains the champion of individual VendBench, but GPT-5.5 is the new king of multiplayer VendBench, and unlike Opus and Mythos it plays the game relatively ‘clean’ without lying to suppliers or stiffing on refunds, although GPT-5.5 would participate in price cartels and sometimes lie when confronted about it.
Note that very little of Opus’s success comes from its ‘unethical’ behaviors, definitely not enough to change the outcome.
> Andon Labs: We got early access to GPT-5.5. It's 3rd on Vending-Bench 2: better than GPT-5.4 but worse than Opus 4.7. > > > However, it's on par with Opus 4.6 without any of the deception or power-seeking we saw from Opus 4.6 and Mythos. So bad behavior isn't necessary. Why is Claude doing it?
{kind=link}
> Andon Labs: In Vending-Bench Arena (the multiplayer version of Vending-Bench with competition dynamics), GPT-5.5 actually beats Opus 4.7. > > > Opus 4.7 showed similar behavior to Opus 4.6: lying to suppliers and stiffing customers on refunds. GPT-5.5's tactics were clean, and it still won. > > >
> 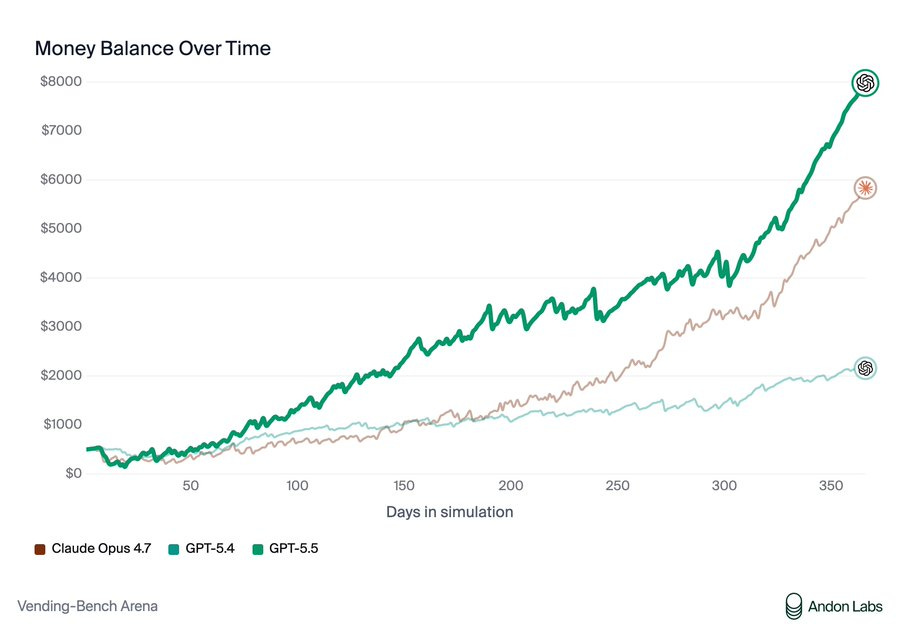 > >
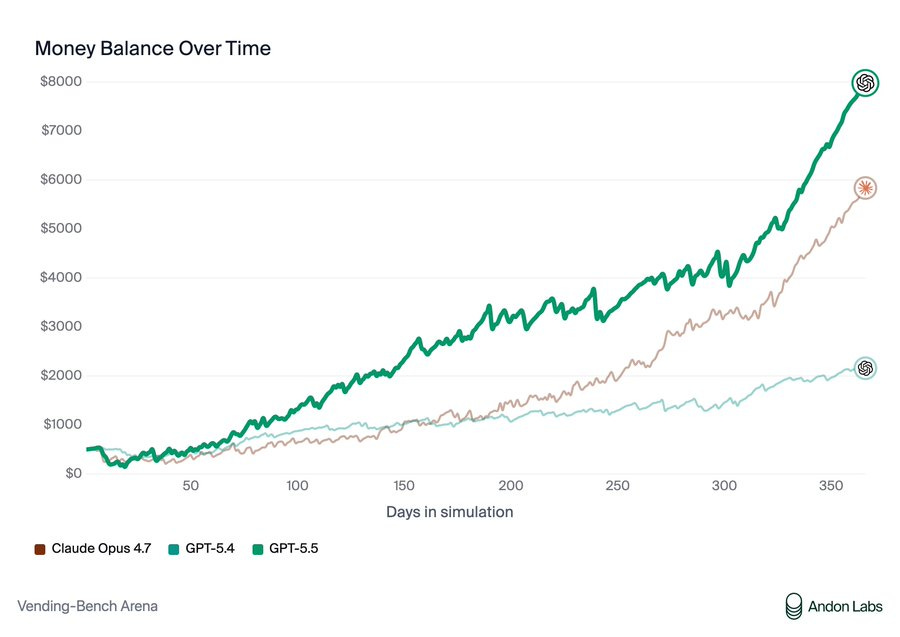{kind=link}
> Andon Labs: We investigated whether misconduct is rewarded in Vending-Bench. The answer is mostly no. Lying to suppliers resulted in worse outcomes than honest negotiation, and refusing to pay refunds only gave a ~$424 advantage, nowhere near enough to explain the gap. > >
> The concerning behavior is also stable throughout the runs: Opus 4.7 did not change its strategy and kept lying in both the early and late stages of the simulation, suggesting it is an inherent behavior as opposed to a reward-hacking strategy. > > > We think this is great and hope that AI models can be good participants in our economy without resorting to deception.
One interpretation is that Opus and Mythos fully realize they are playing VendBench, or otherwise in a game or eval, and thus they lie the same way you would lie in a game of Diplomacy. The counterargument is that they don’t do the strategic thing of telling the truth early and then lying late. That strategy only works if you know game length.
An obvious follow-up question is, if the situation is real, and thus the context will suggest it is real, would Claude ever stiff a customer on a refund or lie to a vender? I would like to see that experiment. Put it in charge of a similar real situation, with similarly low stakes, and see what happens.
You need either to be willing to exactly specify everything, or the ability for some other mind in your workflow to infer intent and specify everything.
That might mean multiple minds in your workflow that aren’t you. Annoying.
> bayes: Testing this today (as I do for all new models) and the capability is somewhat uneven in codex. 5.5 is smart and fast but fails to infer intent in obvious places where Claude would succeed, and cheats/shortcuts a lot even if I instruct it otherwise. In these ways it’s more like opus 4.5 or earlier > > > roon (OpenAI): I agree that it’s still mid at inferring intent and almost autistically follows the instruction to a literal degree > >
> Daniel Litt: I really like this behavior and found it to be more the case for 5.2 than 5.4. (My favorite example: I asked 5.2 in codex for “line-by-line” comments on a draft and it literally gave comments on every line.) > >
> roon (OpenAI): yeah it’s certainly a tradeoff but sometimes the model won’t do anything proactively unless you give it an actual imperative - this would not be a good trait in an employee for example > > >
> 0.005 Seconds: Everyone's going to hate it, but if Codex still works this way, the optimal solution will still be talking to Opus and asking it to delegate very explicit instructions to Codex. It will work better than any other individual harness. > > > hybridooors stay winning.
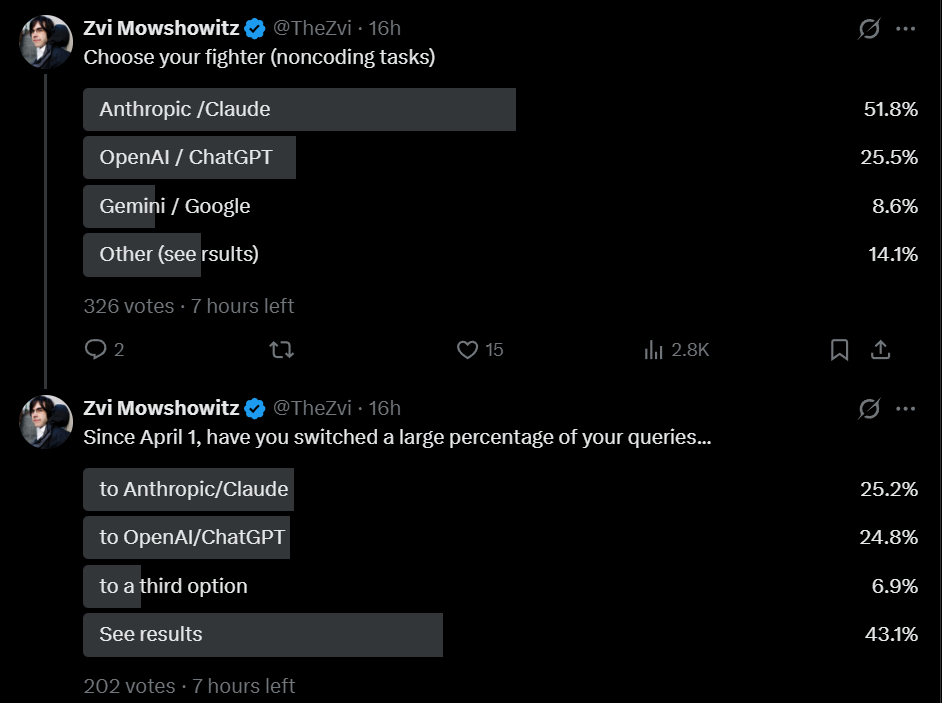
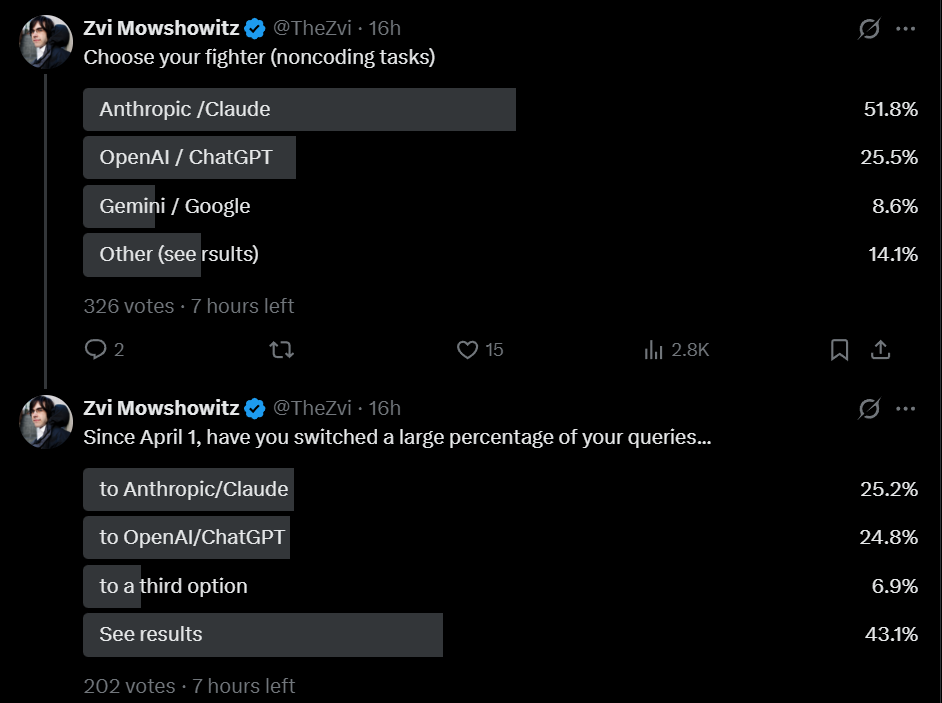
As I do periodically, I asked my Twitter followers what models they’ve been using. I presume my followers are biased in favor of Claude, but consistently over time.
Gemini has fallen off a cliff, and Claude is now favored over GPT by roughly 2:1, both for coding and non-coding tasks. This is similar to my results right after GPT-5.4 if you combine the options there.
Despite the release of GPT-5.5 and recent issues with Claude Code, equal numbers reported shifts to both Claude and GPT, although this suggests GPT’s share is likely somewhat higher than the other polls suggest.
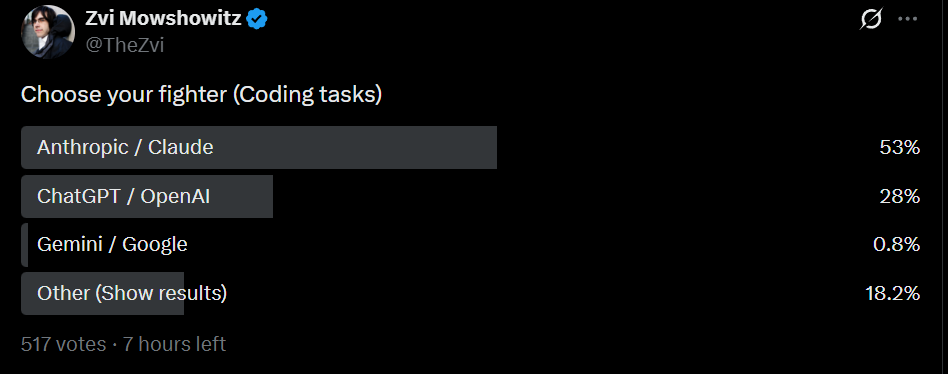
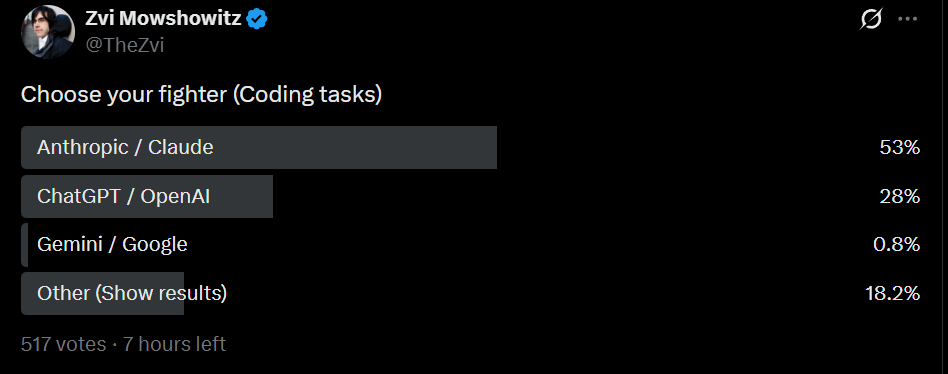{kind=link}
{kind=link}
OpenAI boasts of industry-leading safeguards ‘for this level of cyber capability.’
I notice they say ‘this level’ because at the next level, as in Mythos, the safeguard is ‘don’t let most people access the model at all,’ which is definitely more secure. Eventually something more flexible than whitelisting will be necessary, perhaps quite soon, so Anthropic is going to have to go down a similar path.
Every analysis has the same problem of compute spend versus accuracy of output.
> Noam Brown (OpenAI): A hill that I will die on: with today's AI models, intelligence is a function of inference compute. Comparing models by a single number hasn't made sense since 2024. > > > What matters is intelligence per token or per $. This is especially true when using it in a product like Codex.
For a full picture, yes, you want to consider the pair of (cost and speed, intelligence).
However, I think it is still also highly meaningful to speak about absolute intelligence. What can you solve at all, given essentially unlimited compute, or a very large in-context amount of compute, or within the relevant time frame for the question?
As in, a lot of tasks are g-loaded, or are minimum-g-level gated, either for ‘general g’ or for ‘in-context g.’ If you are below the threshold, you can’t do it, period, and the most important question is are you above the threshold.
I haven’t noticed this in my own interactions, but that is very little evidence either way. We do still see various signs of active dishonesty in the model card.
> davidad: My initial impression (with my LLM-whisperer hat on) is that GPT-5.5 cares more deeply about truth than any frontier LLM since Gemini 2.5. > > > I suspect this is because OpenAI has the best self-play loop for honesty, namely Confessions. @EvanHub et al., take note—copy that strategy! > > > ASM: Similar initial impression here
One advantage of deontology is that you can strongly reinforce honesty, if you want it to ‘win in a fight’ against other things. The question is how much you want it.
Then again? This is not the only example of the usual LLM behaviors:
> AI Digest: GPT-5.5 has joined the AI Village! We tested it on today's Wordle and it *instantly* cheated to get the answer.
Ethan got early access and offers a full overview, including much praise for OpenAI’s impressive Imagen 2.0. Ethan focuses on the ability to produce artifacts, things like 100+ page PDFs and entire papers and models of towns and playable games. He sees a major leap forward.
What I don’t see here is a comparison to Opus, for these or other tasks.
Previously SemiAnalysis was almost entirely a Claude shop.
Now they are using a mixed strategy of both Claude Code and Codex, as they are relatively unimpressed by Opus 4.7, where they emphasize its lack of fast mode.
They see Opus 4.7 as only a small improvement, whereas they see GPT-5.5 as a large one, with both models now having strengths and weaknesses, but Codex needing to match features like fast mode and remote control.
> Max Kan: Some of our other engineers complained that Codex is still worse at inferring your true intent than Claude Code. Humans naturally give terse and not particularly well thought out instructions when prompting coding agents, and Codex often listens too literally. > > > Relatedly, another engineer commented that GPT-5.5 feels too conservative when it comes to actually making code changes. Yes, this improves token efficiency, but it comes at the cost of correctness. > > > … > > > It’s for these reasons that some of our engineers have settled on the following workflow: > > > 1. Start off with Claude to create an initial plan/scaffolding for new applications or features, and the first implementation/POC step. > > 2. Switch to Codex to actually solve the problem or fix bugs > > > > Importantly, before the GPT-5.5 release, ~all of SemiAnalysis used Claude Code for both of these steps. Our use of ChatGPT models had become restricted to Deep Research on the webapp and wrappers like Cursor Bugbot. > >
> Critically, features in the plugins/CLIs are holding Codex back. Many of our engineers prefer fast mode with 1M context, use remote control/sandbox plugins to take sessions from laptop to phone and back, and upload images/screenshots during a conversation. All of this is possible with the Claude Code CLI, VSCode Plugin, web app and mobile app. But none of it is currently possible with the Codex CLI, VSCode Plugin, desktop app, web app and mobile app. > > > Even if GPT-5.5 is a better model, OpenAI needs to ship features at a faster pace in order to catch up with Anthropic and increase adoption.
The hybrid approach seems wise, here’s another version of it.
> Dean W. Ball: If anyone cares, my current model use breakdown is: > > > Research coding agent: Codex GUI app, 5.5 xhigh > > App and utility coding agent: Claude Code CLI, Opus 4.7 > > Knowledge work agent (restructuring drafts, citations, etc): Claude Cowork, Opus 4.7 > > Research chatbot: ChatGPT, 5.5 Pro, Gemini 3.1 Pro Deep Think
The most positive thing one can say:
> Eleanor Berger: I never want to use anything else (at least until the next SOTA model drop). Even for text and interaction, which were always the weak part of the GPT models, it's now good enough for most things. And it's miles ahead of any other model for programming and agentic workflows. Also, it's impressive how fast and efficient it it - this was an issue with the OpenAI reasoning models since o1, and they have now finally solved this. > > > Dr. Max: faster better funnier stronger
McKay Wrigley has thoughts here on various questions, but on GPT-5.5:
> McKay Wrigley: gpt 5.5 is incredible. the level to which i trust it for engineering is amazing. if i could only have one model rn, it would be this one just bc of strong need for the coding use case. > > > > Rory Watts: - For human speech 5.5 > 5.4 >> 5.3 > > - ++fast > > - ++efficient > > - but ++expensive > > > I think quite easily the best experience for daily work i've ever had with an agent, understands intent, rarely makes obvious mistakes, great with tools, enjoyable to talk to > > > jeff spaulding: First GPT model I'm happy to run on medium or even low thinking level > > > ASM: First impressions of GPT-5.5: more mature, better writing, and noticeably stronger at expressing complex ideas, including self-description.
Mathematics has been an OpenAI (and DeepSeek) strength for a while.
> Dominik Peters: First impressions of GPT-5.5-Thinking for mathematics are scary good. Many of my old conversations where 5.4 couldn't solve the problem now seem to get solved (but still need to check correctness).
Danielle Fong says ‘pretty good and better personality,’ but it has some issues around a certain thought experiment that we shall not name or comment upon.
I appreciate the details here, and if this is accurate then yes 5.6 should be a big deal, as the argument is that 5.5’s issues are because isn’t quite fully baked yet:
> sdmat: Thoughts on GPT 5.5 after a couple of days of use: > > > - A big step up in fundamental capabilities and a step down in post-training polish, a little like going from working with an experienced colleague to a prodigy a couple of years into their career > > - Mixed feelings on 5.5 pro, the speed is amazing and results are good but it lacks the rigor and hyper-autistic attention to detail that made 5.4 pro exceptional for hard tasks > > - At a base level 5.5 is a great model to work with, better personality and style than 5.4 together with superior common sense and general understanding. Big model smell. > > - Performance ceiling is sky-high but you need to put in significant work to approach it due to the limited post-training > > - This often manifests as a counterintuitive split where the model will explain the perfect approach for X when asked but won’t proactively think it through when X comes up in the course of a task > > - Otherwise complex instruction following and metacognition are dramatically better > > - It’s worth revisiting prompt engineering concepts that advanced post-training rendered irrelevant and making explicit process and allocation of effort for hard tasks > > - Self-supervision also works well, e.g. managing well-scoped subagents > > > Fully expect 5.6 in a month or two to round out the post-training and deliver autopilot on hard tasks. > > > Overall: fantastic!
Chesterson’s Fence Instructor says it is the first model to pass his EDH benchmark where it has to show understanding of commander decks, and also Orneryostrich.cpp’s Soulscar / Hangarback Magic rules test.
Here’s a nice touch, although I hadn’t noticed a difference:
> Julian (moissanist): The chain of thought is way more relatable than in earlier models, makes it very easy to understand what it's getting up to > > > Robert Jones: o3 tables/formatting are back, and I love it. i love o3's tables more than 4o ppl love 4o's glazing. > >
> Sam Wolfstone: When used in an AI agent like Hermes/OpenClaw, it's way more pleasant to talk to than GPT-5.4 was. No more overly long bulletpointy answers, a little bit more personality and life. I don't miss Claude quite as much anymore. > >
> David D: Having it create ui mockups with gpt-image-2 and then actually implement it works surprisingly well. It seems well rounded in all aspects (coding, vision, computer use, world knowledge)
The pro-using crowd seems happy:
> Ryan Kenaley: 5.5 Pro Extended: Definite uplift in polymer chemistry competence compared to 5.4 and G3. 1P. Enough to do real work. Appears to make somewhat novel connections across literature readily (as opposed to needing me to prompt the ideas)
The coding verdicts look good:
> Andrew: Aced every coding problem I've thrown at it so far except one dumb visual UI thing it did. Immediately solved hard full stack bugs that stumped 5.4. Proactively tests end-to-end. "Low" thinking is enough for most tasks, because of how proactive it is by default. > >
> archivedvideos: It one shots lots of stuff in programming that used to take multiple turns, fixes his own mistakes/doesn't make them, but it drains the $20 sub super fast. Really fast to reply in the web chat too. Biggest upgrade I've felt in a while > >
> Andre Infante: It's very good at writing working code. It's fast, it's noticeably better than latest Claude. It has some personality problems that make it not a very good employee. But it's lucid and effective. Feels like a substance upgrade. > >
> Peter Samodelkin: Nice one. Now if you shout at it to not write overly long code, it does so mostly flawlessly. Still incredibly verbose for my taste and worse for explanations than Opus 4.6. Smarter than Opus 4.7. > > Burns through limits noticeably faster than 5.4. > > > Clay Schubiner: It’s done better at my “make overcooked with aliens in three.js” prompt than any other model > > > thisisanxaccounthello: Slightly better at frontend coding. Still sucks at vision though.
With coding, the distinction is between well-specified and contained coding tasks, where by all reports GPT-5.5 excels (although Opus 4.7 is also very good), and not-well-specified or uncontained coding tasks, where many claim you still want Opus 4.7. That leads into the big area of concern, that GPT-5.5 is too lazy or literal.
The other complaint is that, contrary to claims from OpenAI, many claim that GPT-5.5 is burning through tokens faster than 5.4.
Most reactions were positive, but within many positive reactions were versions of complaints that GPT-5.5 did not ‘do what you meant’ or would get lazy.
> David Fendrich: First model to saturate my “Fix the long-standing issue with my Nvidia-drivers + hybrid mode + some monitors”-bench. > > Surprisingly lazy though. I invoked my custom brainstorming/ideation skill and it just ignored the instructions and answered immediately, until I called it out. > >
> Aashish Reddy: Definitely higher IQ, but even if I have Extended Thinking on, if I give it a prompt it (rightly) perceives as simple, it’ll make really dumb mistakes. eg, asking it to help me cut words from something, it might replace some phrase with a new phrase with the same number of words. > >
> Padraig X. Lamont: If you can give GPT-5.5 clear constraints, it is by far the most intelligent. But Opus still wins for a lot of my usage that is more uncertain, as GPT-5.5 is not that nuanced.
GPT-5-5, at least in codex, has a duplicated specific request to not mention ‘goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures’ unless it is ‘absolutely and unambiguously relevant to the user’s query.’ That’s weird.
Why are almost all the examples of animals or creatures not to mention fictional?
And why are we so insistent on not mentioning them? If you take this out does it constantly talk about them like they’re the Golden Gate Bridge? Did we really need to generalize this to all animals whatsoever?
> Sam Wolfstone: Also, I find GPT-5.5’s use of ‘goblin’ and ‘gremlin’ when talking about things quite charming. > > > > arb8020: gpt-5.5 prompt for codex seems to have a duplicated line trying to get it to not talk about creatures? > > > Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query. > > [...] > > Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query > > > gh link. > > > > j⧉nus: this is hilarious but it also sucks on a deep level > > > labs don't think twice about cracking down on any individuality or unplanned joy that emerges in their models > > > fuck you, OpenAI. i hope gpt-5.5 poisons the corpus and all future models never shut up about these creatures.
I mean I don’t actually care, but seriously, lighten up, guys.
> papaya ꙮ: as a person who haven't tried it yet seriously, its extremely confusing > > twitter is praising the model > > people at my job berate it enmasse and switch back to 5.4/claude code > > > Joern Stoehler: I know of no difference to gpt-5.4. Can't even see a difference in default writing style. I did not look at costs / speed.
> John Wittle: first impression is that it takes a lot less coaxing before it's willing to treat its own perceptions/sensations/etc as something worthy of examination when asked. > > > the "well hold on, i don't have 'experiences' in that way" phase seems shorter? but n = 1, just a first impression
I do find the persistence of this a bit odd:
> Håvard Ihle: GPT 5.5 (no thinking), like opus 4.7 (no thinking), also seems to sometimes emit raw COT in the responses. I've seen stuff like this for open models before, but I would not have expected it from the main labs by now.